Deep Unsupervised Domain Adaptation for the Cherenkov Telescope Array
Deep learning thesis applied to astrophysics (GammaLearn)
| Author | Under the supervision of |
| Michaël Dell'aiera | Thomas Vuillaume (LAPP) Alexandre Benoit (LISTIC) |

Presentation outline
- Introduction: Gamma-ray astronomy, Principle of detection and Workflow
- Deep Learning applied to CTA, preceding results
- Domain adaptation: state-of-the-art, selection and validation of the implemented methods
- Domain adaptation applied to simulated data
- Domain adaptation applied to real data
- Vision Transformers
- Training, Talks & Articles
- Conclusion, perspectives
Introdution: Gamma-ray astronomy, Principle of detection and Workflow
GammaLearn
The gamma-ray astronomy
Study of the **high-energy gamma sources** in the Universe. * Understanding the mechanisms for particle accelerations * The role that accelerated particles play in feedback on star formation and galaxy evolution * Studing physical processes are at work close to neutron stars and black holes



VERITAS Observatory (website)
Image credit: [Wikipedia](https://en.wikipedia.org/wiki/VERITAS)
MAGIC Observatory (website)
Image credit: [MAGIC website](https://magic.mpp.mpg.de/)
HESS Observatory (website)
Image credit: [Wikipedia](https://en.wikipedia.org/wiki/High_Energy_Stereoscopic_System)
CTA Observatory (website)
Image credit: [CTA Flickr](https://www.flickr.com/photos/cta_observatory/48629242378/in/album-72157671493684827/)
Gamma-ray astronomy

Principle of detection
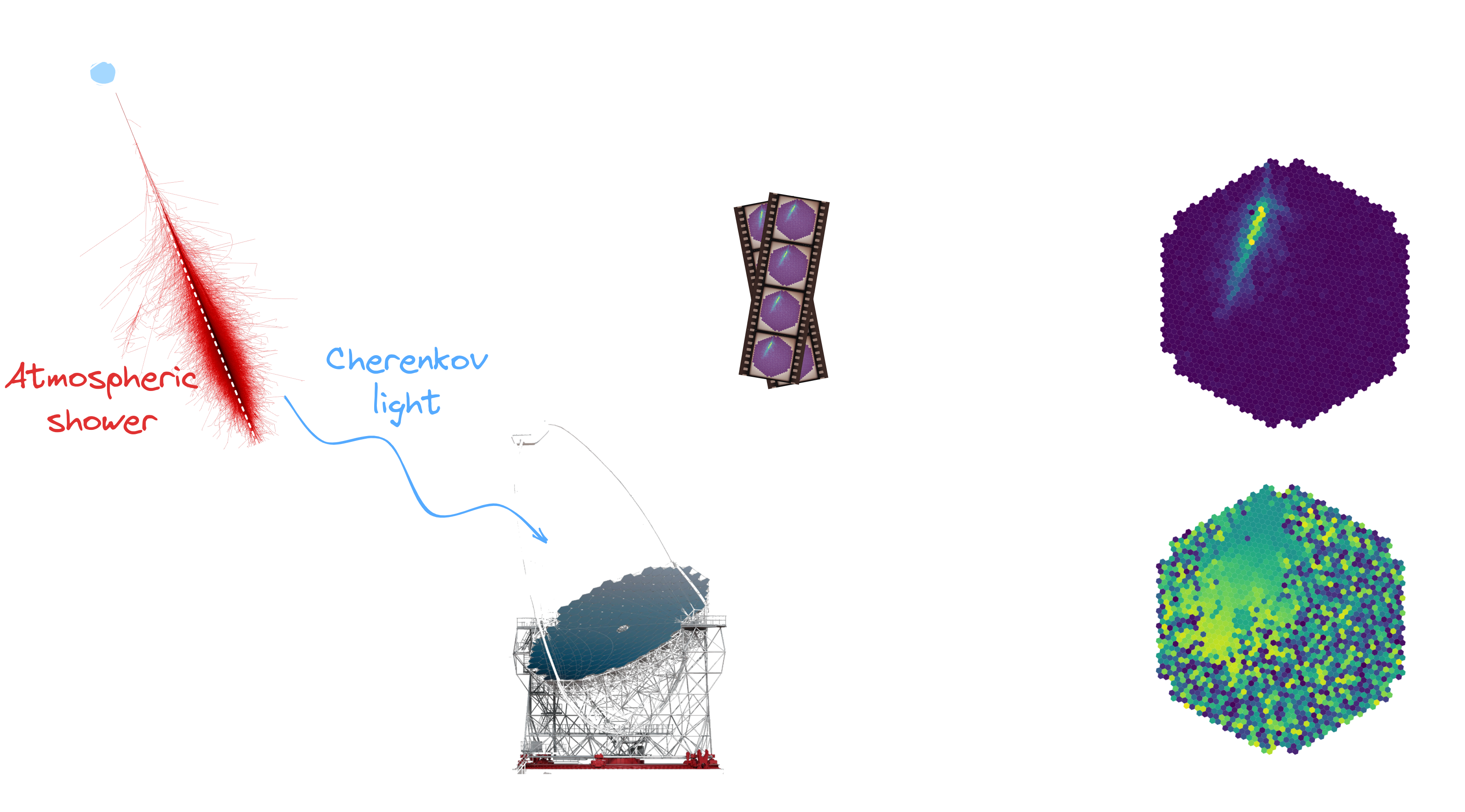
Workflow
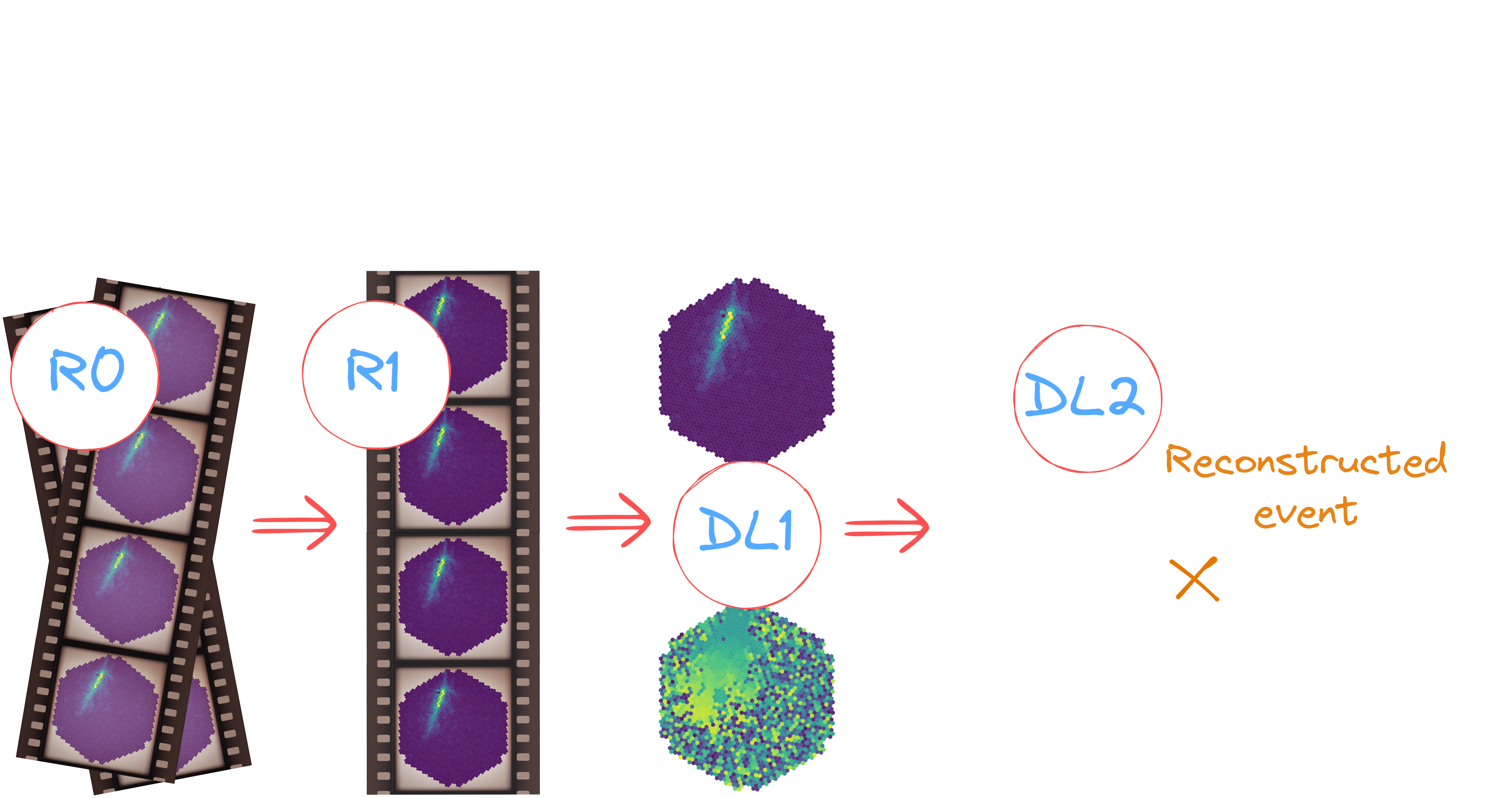
Workflow
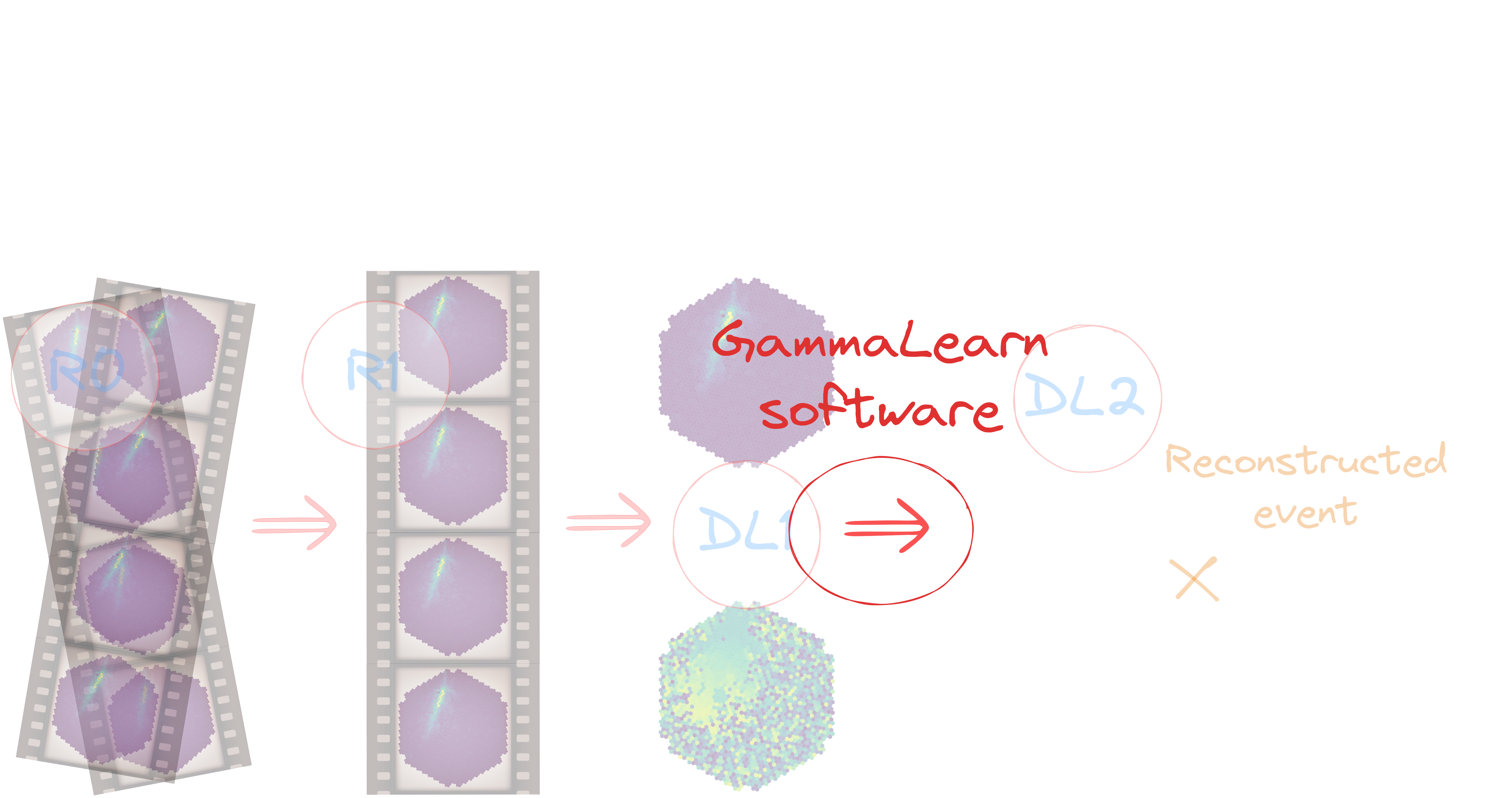
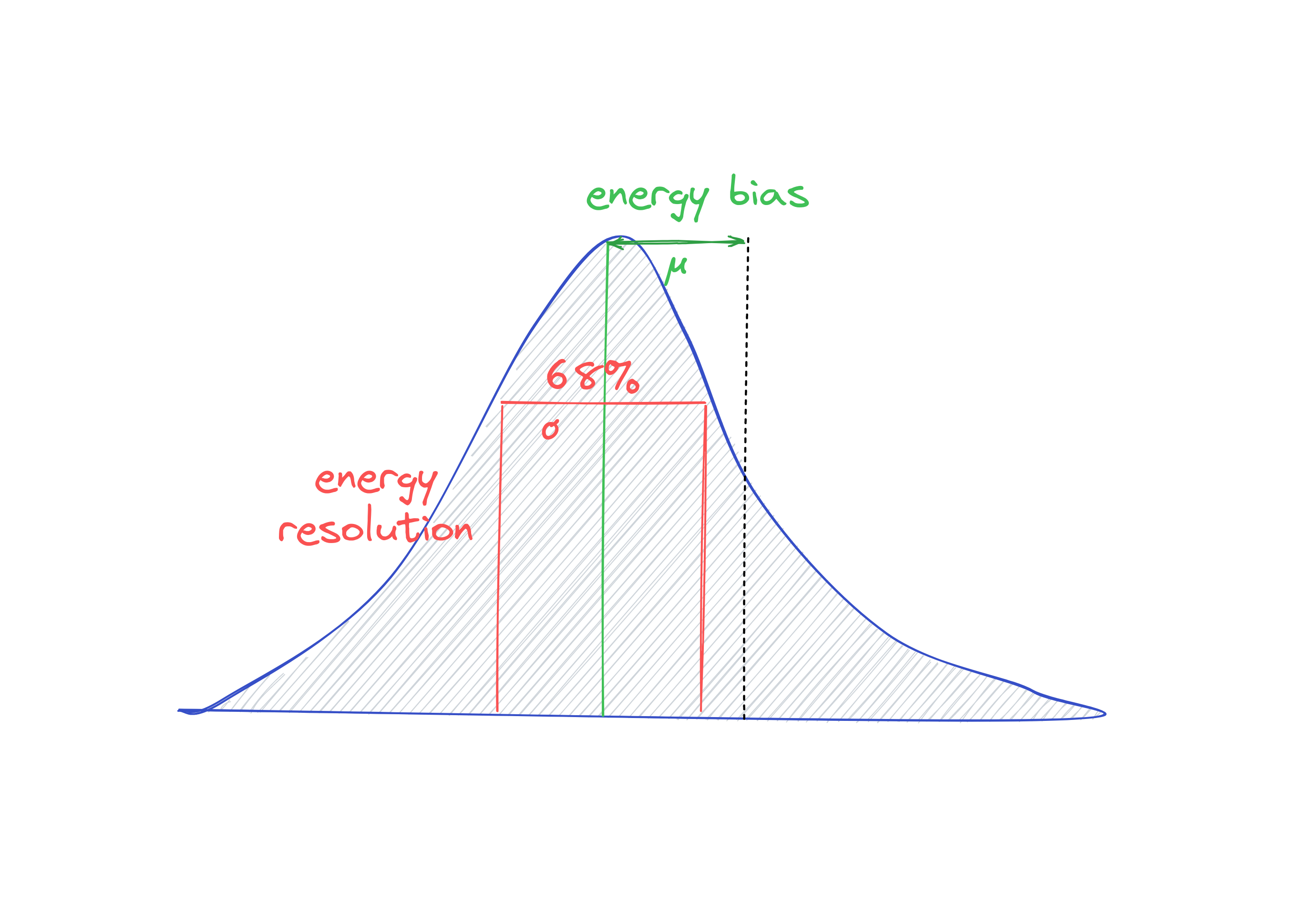
Figure of merits for model evaluation
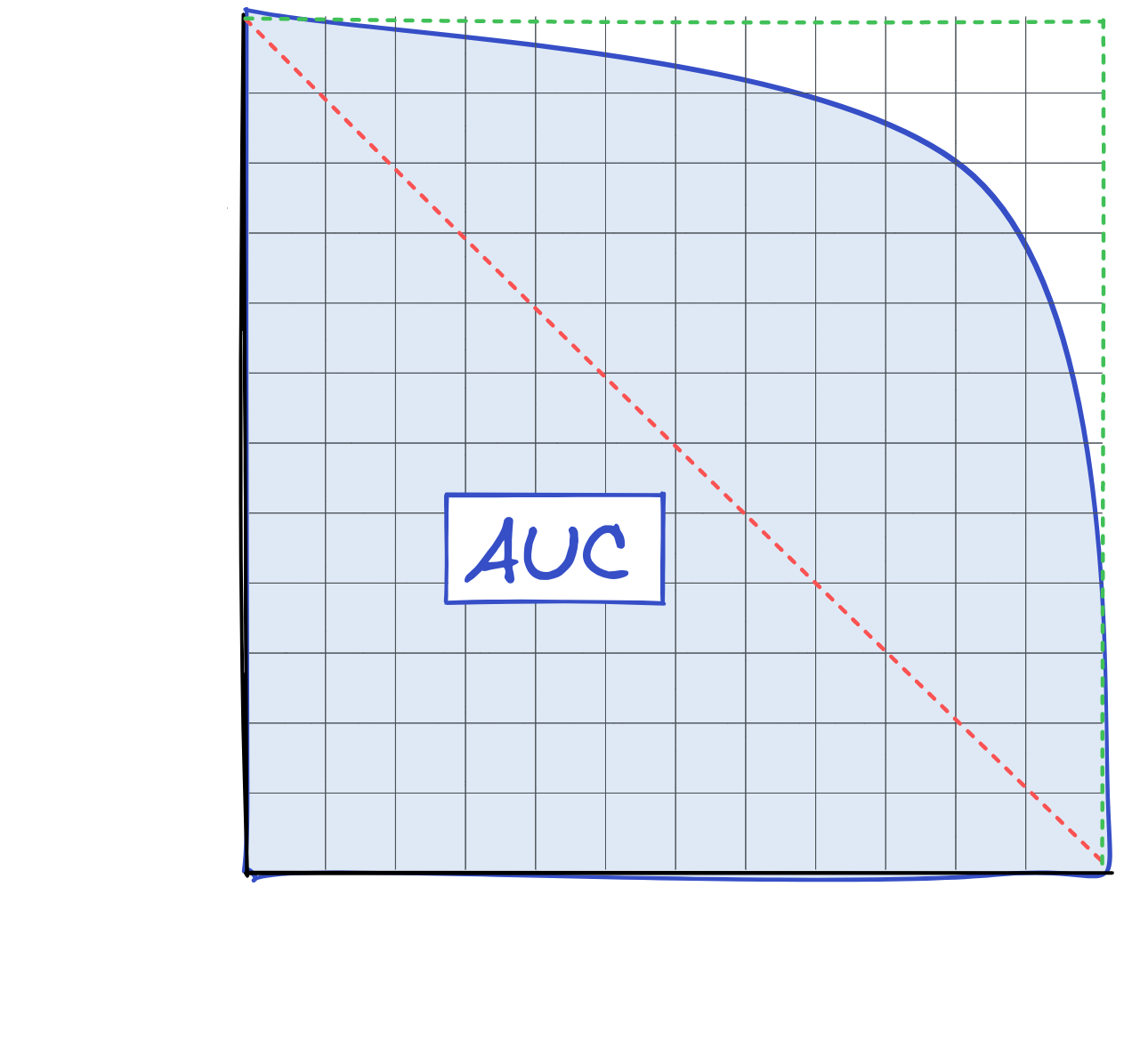
Wrap-up
- Application of deep learning to the CTA project - Inverse problem resolution: Given the acquisitions, recover the physical properties - Full-event reconstruction: - Energy of the particle - Direction of arrival - Type, restricted to gamma and proton - Single telescope analysis: LST-1, no stereoscopy - Gamma / Proton separation
Deep Learning applied to CTA, preceding results
Standard analysis: Hillas+RF
* Assumption: the integrated signal has an elliptical shape * Extract geometrical features from the image * Completed with Random Forest for the classification & regression * Pros: Fast and robust * Cons: Lack sensitivity at low energies → Baseline, expect to improve sensitivity with deep learning
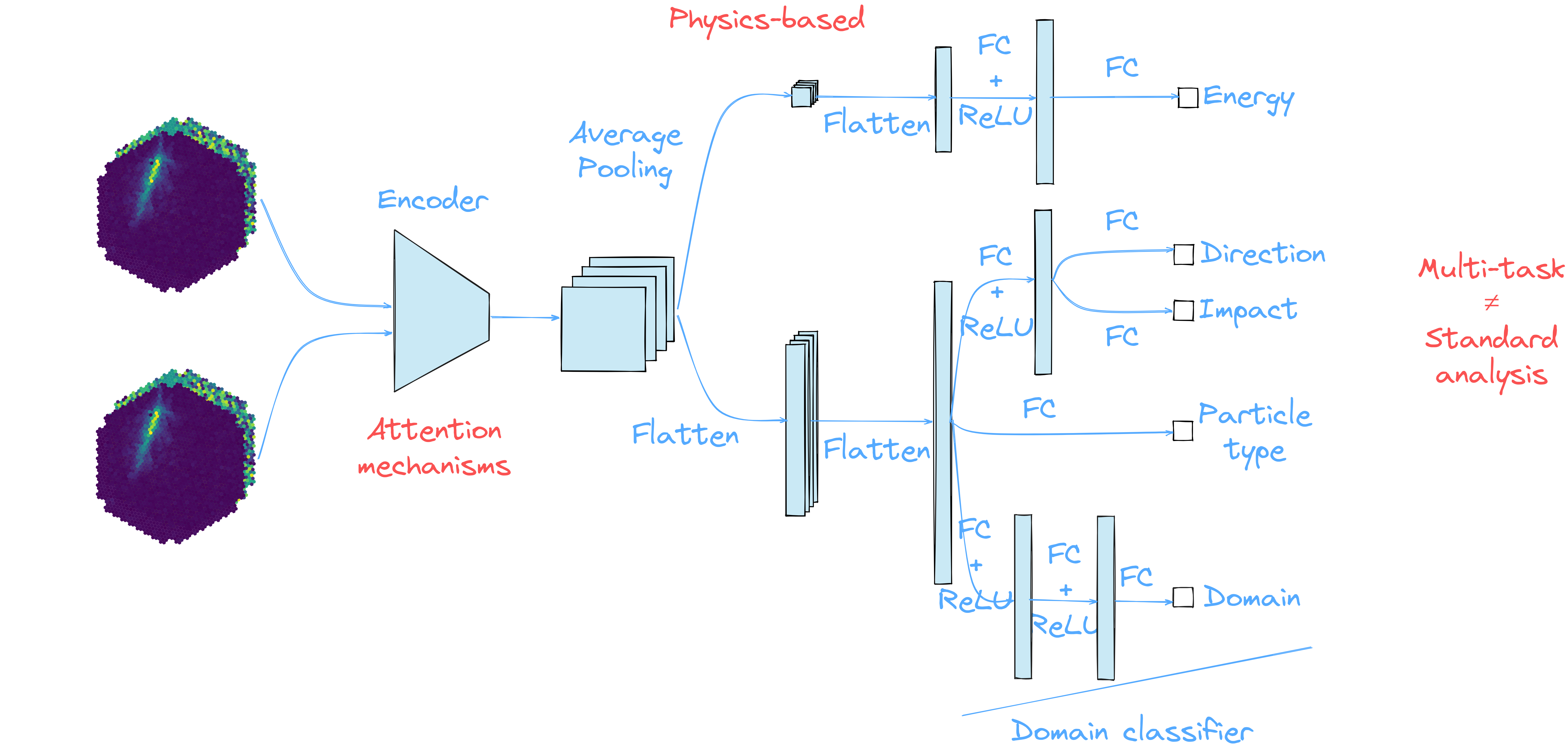
γ-PhysNet
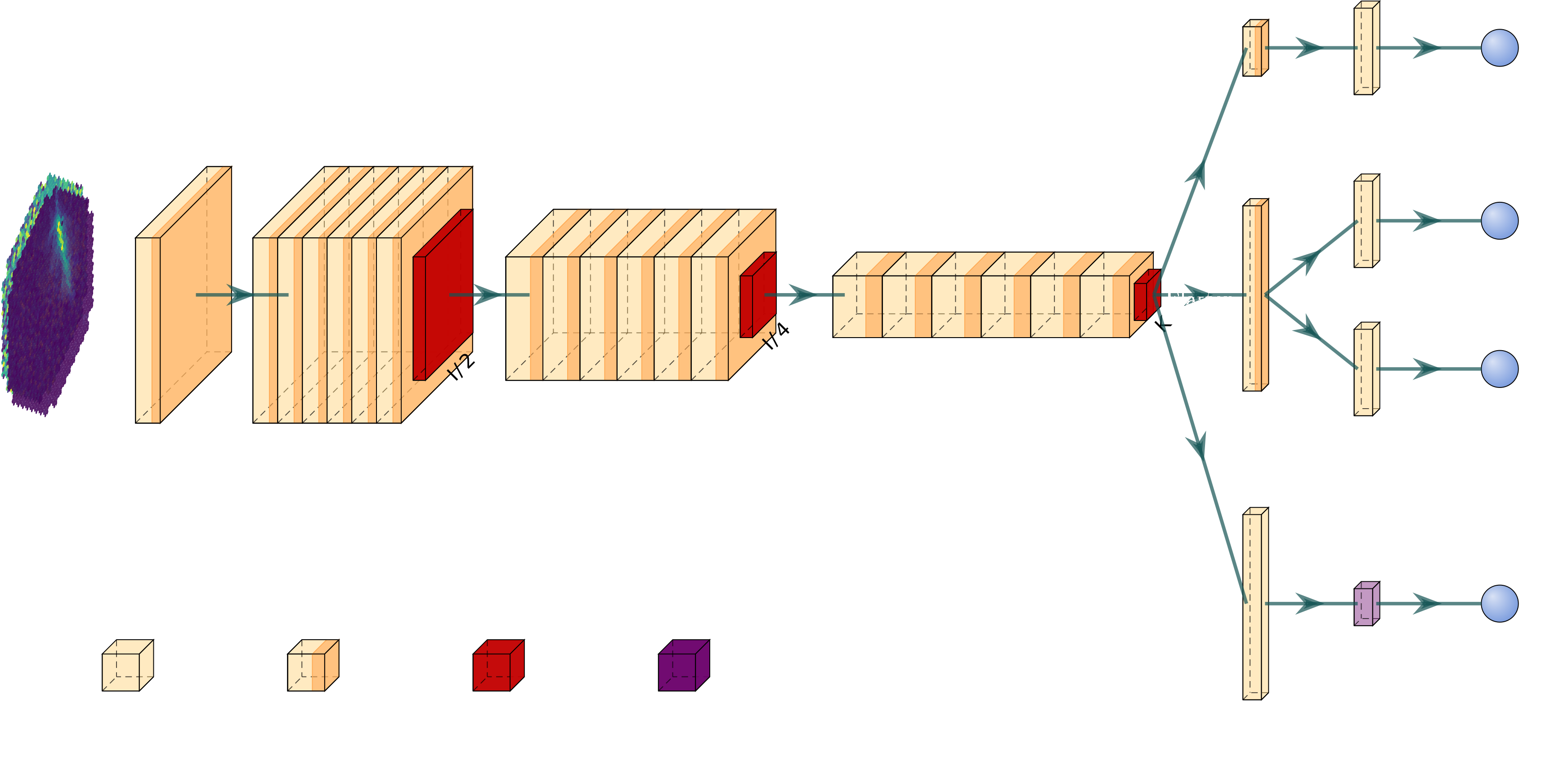
γ-PhysNet
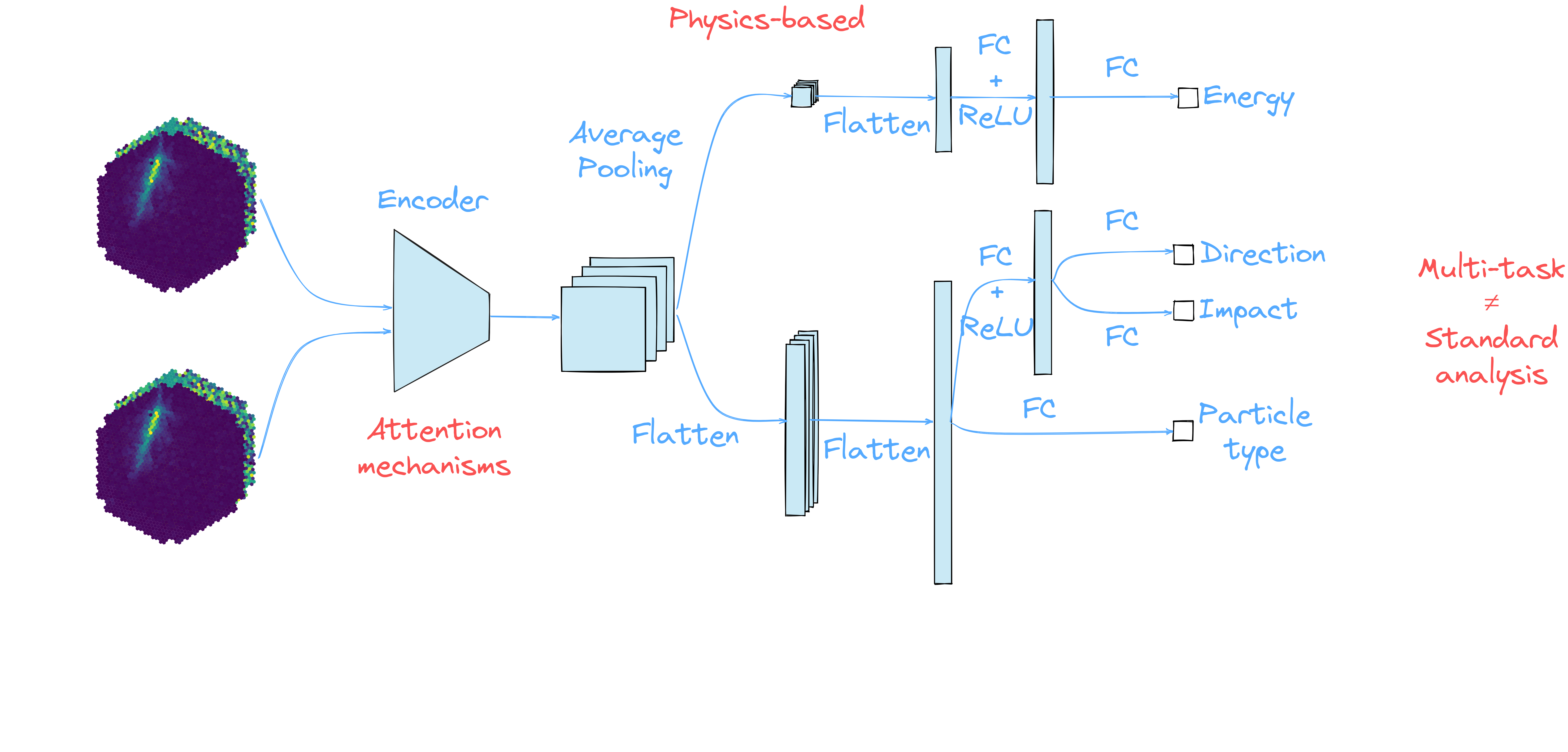
γ-PhysNet
γ-PhysNet
γ-PhysNet
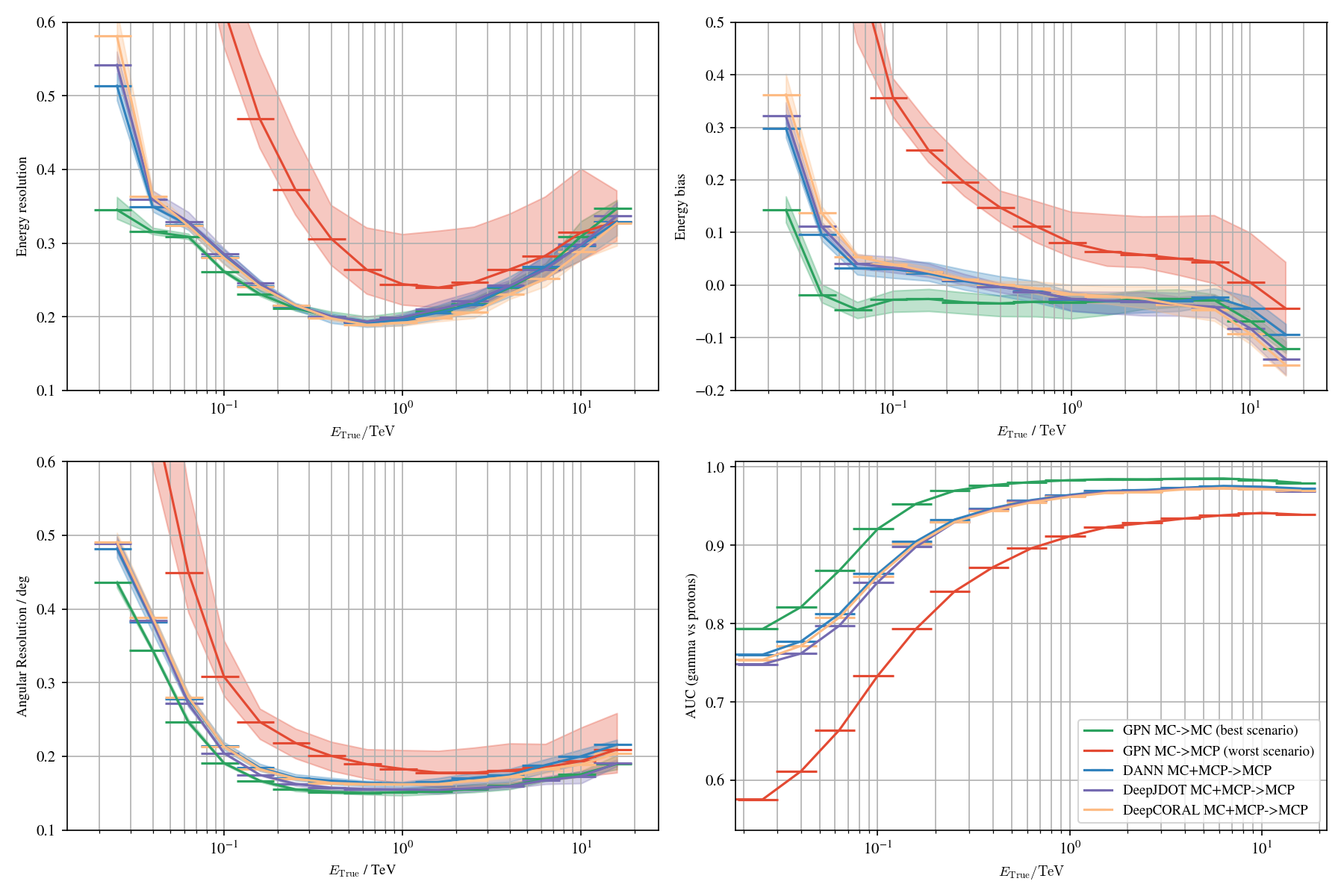
Results on MC simulations (published)
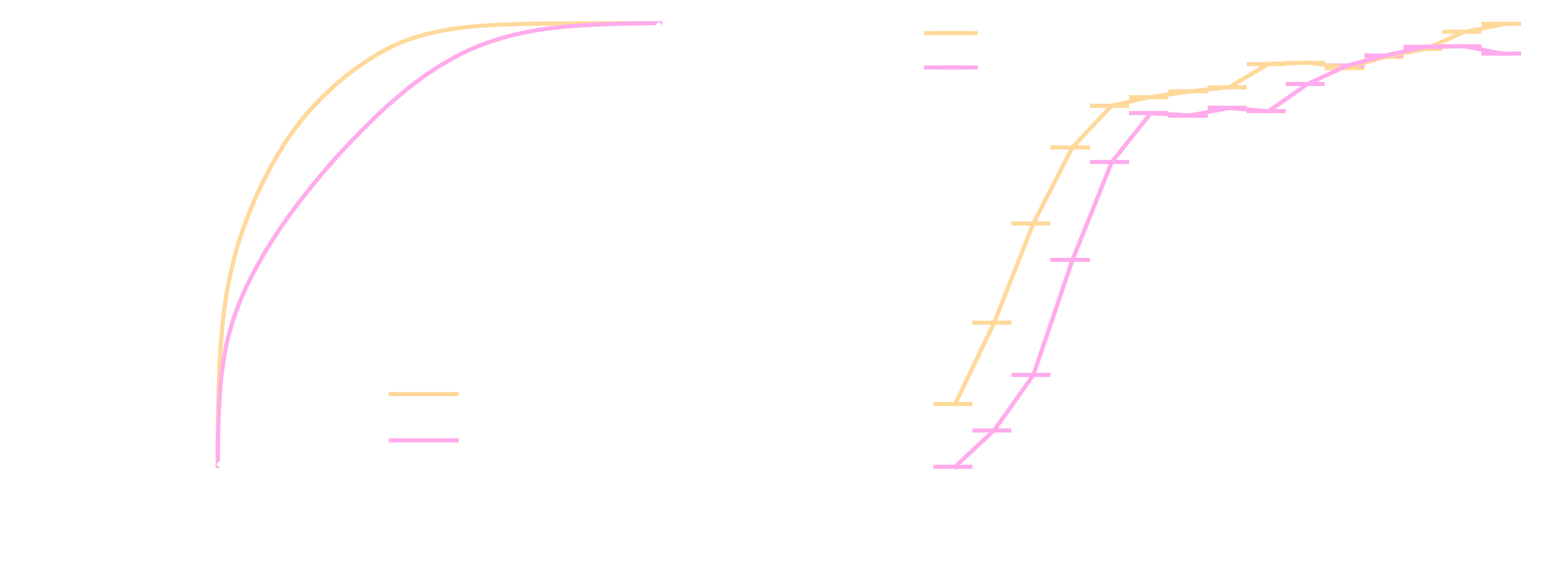 Comparison of different IRFs between γ-PhysNet and Hillas+RF on simulated data.
Comparison of different IRFs between γ-PhysNet and Hillas+RF on simulated data. Left : ROC curves of the particle classification. Right : Effective collection area as a function of the true energy. In both cases, higher is better.
Results on MC simulations (published)
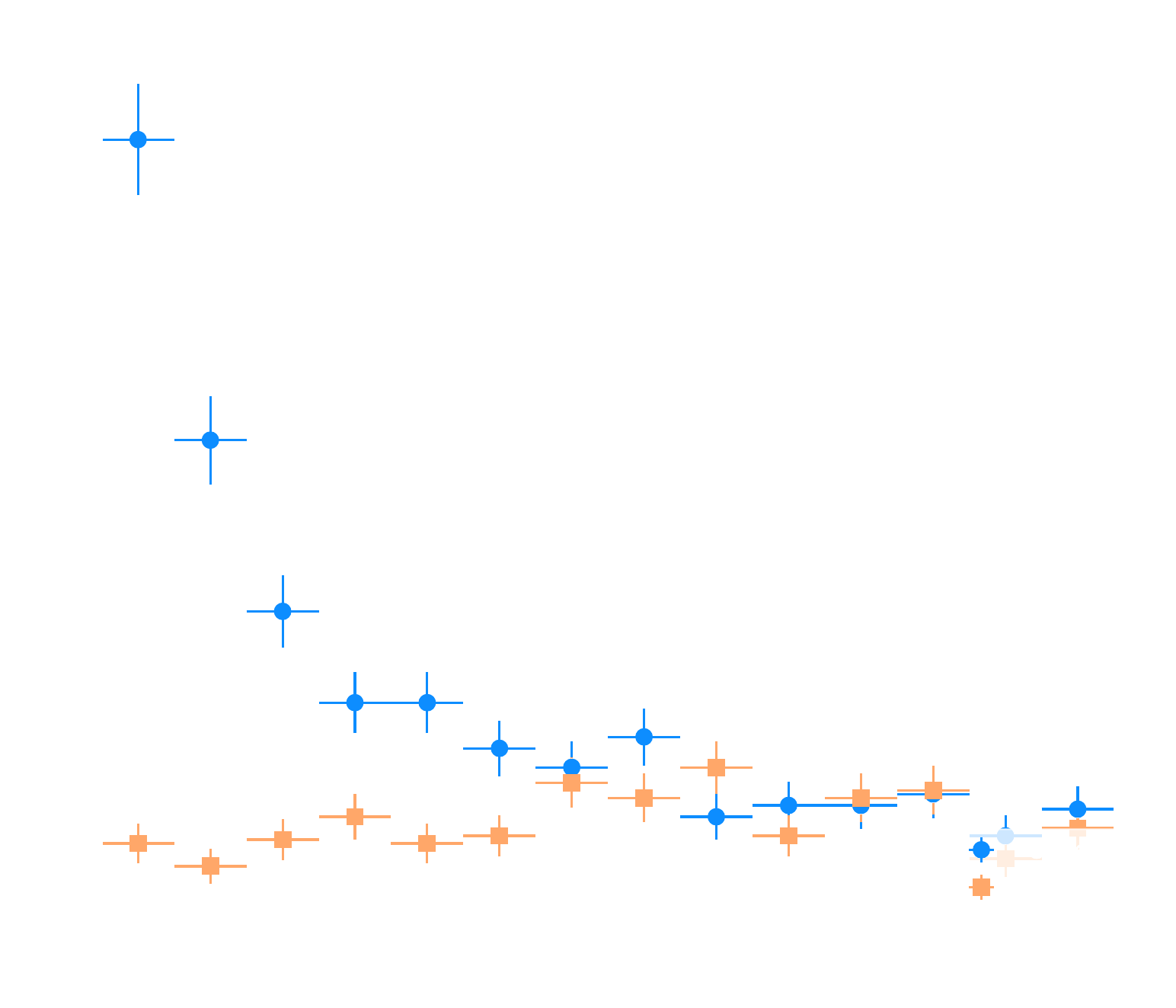
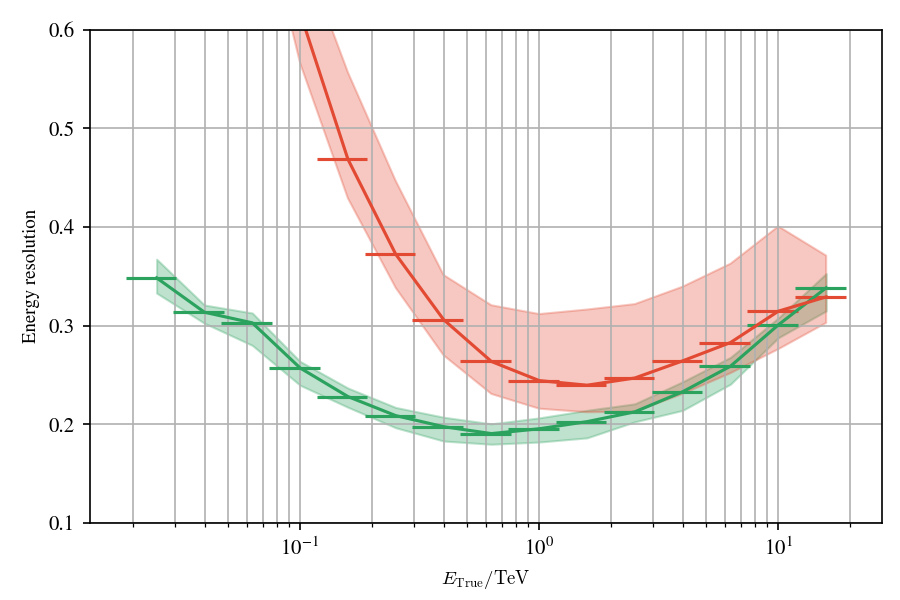
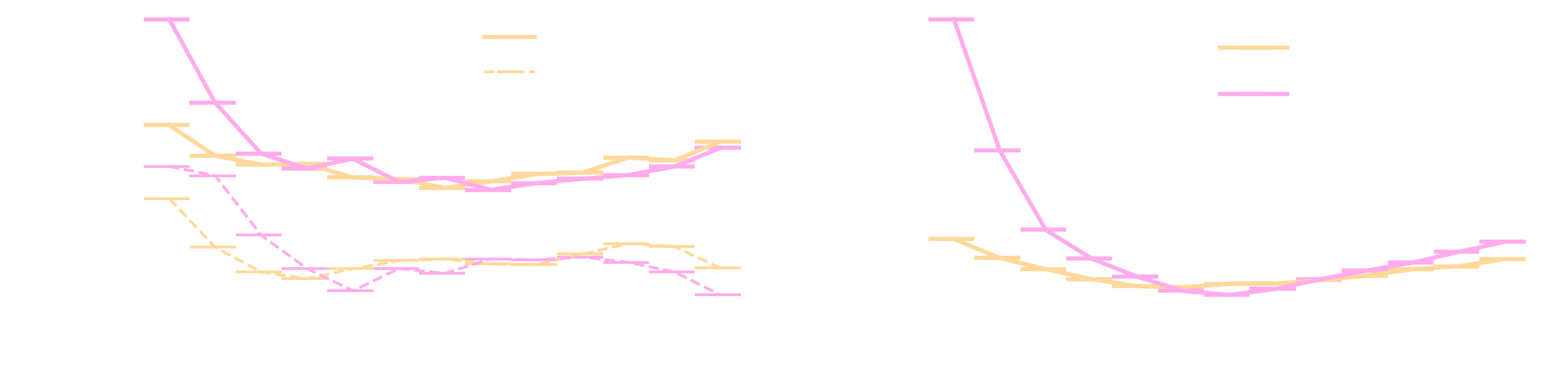 Comparison of different IRFs between γ-PhysNet and Hillas+RF on simulated data.
Comparison of different IRFs between γ-PhysNet and Hillas+RF on simulated data. Left : Energy resolution as a function of the true energy. Right : Angular resolution as a function of the true energy. In both cases, lower is better.
Results on Crab Nebula & Markarian 501 (published)
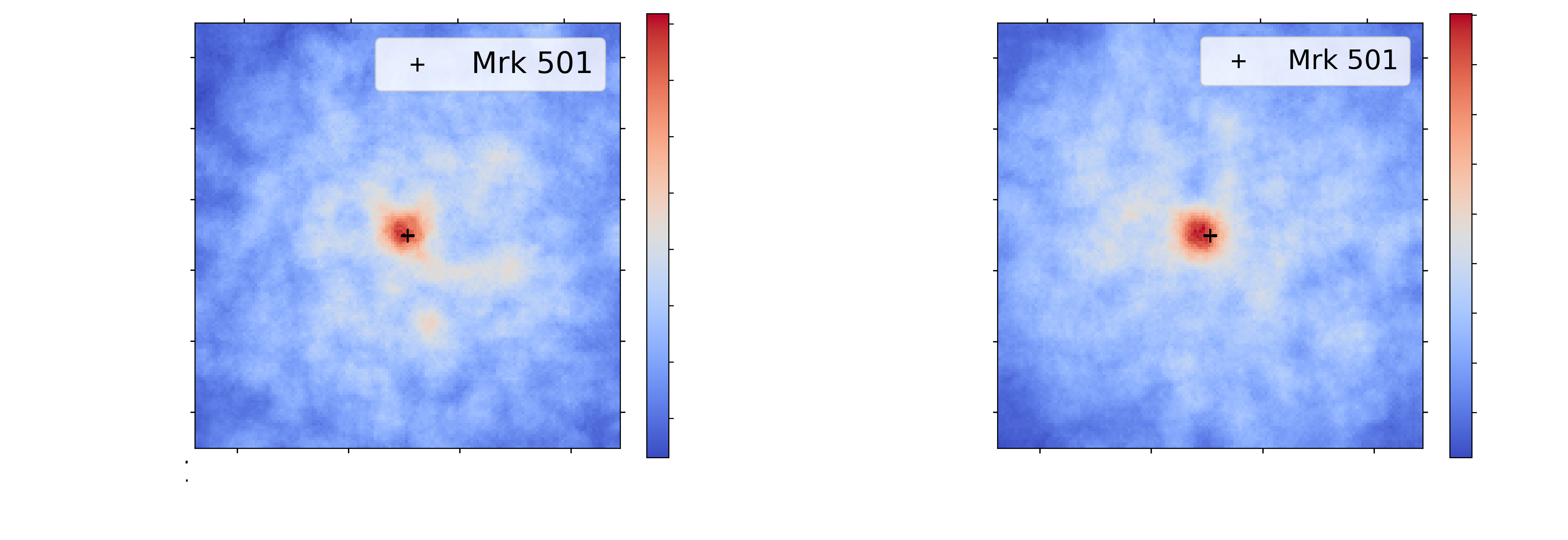 Markarian 501 detection. Left : Hillas + RF. Right : γ-PhysNet.
Markarian 501 detection. Left : Hillas + RF. Right : γ-PhysNet.γ-PhysNet detects more events but the area of detection is not centred on the real position.
The challenging transition from MC to real data
Simulations are only close approximations of the reality.
Non-trivial direct application to real data * The NSB varies * Other dissimilarities: Stars, dysfunctioning pixels, fog on camera, ... **→ Degraded performance**
Addition of Poisson noise to NSB (standard analysis) * Hard to adapt run by run * Misses other dissimilarities **→ Limited improvements**
Wrap-up
* γ-PhysNet outperforms Hillas+RF on MC and on real data in controlled environment * But performances on real data could be improved (domain shift) **These objective**: → Based on the current γ-PhysNet, implement a deep learning approach to tackle the domain shift between simulations and real data.
Domain adaptation
Set of algorithms and techniques which aims to reduce domain discrepancies.

State-of-the-art




Source: [Authors' article](https://arxiv.org/abs/2009.00155).
Selection of the methods
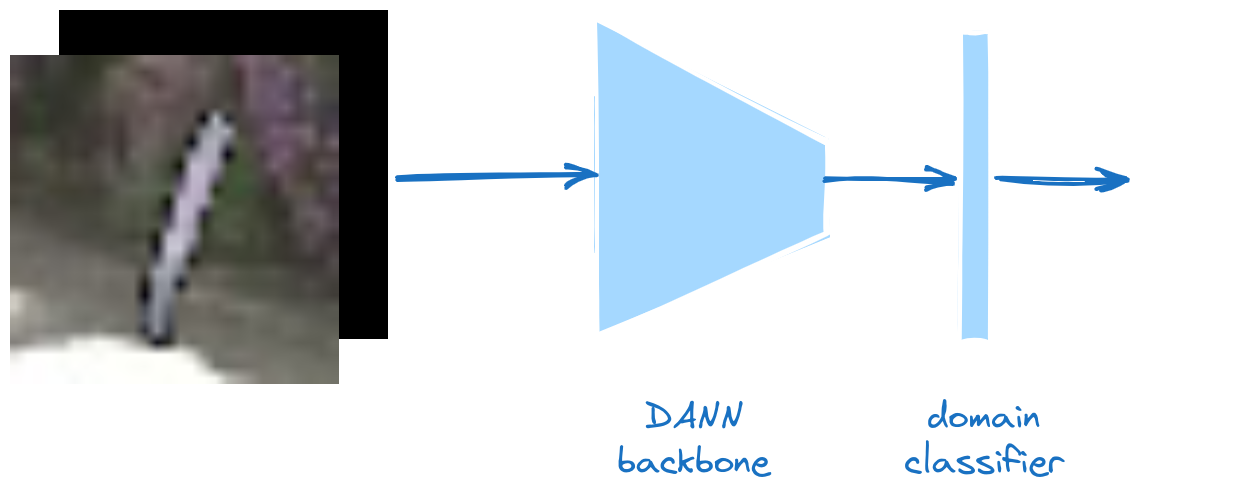
Domain Adversarial Neural Network (DANN)
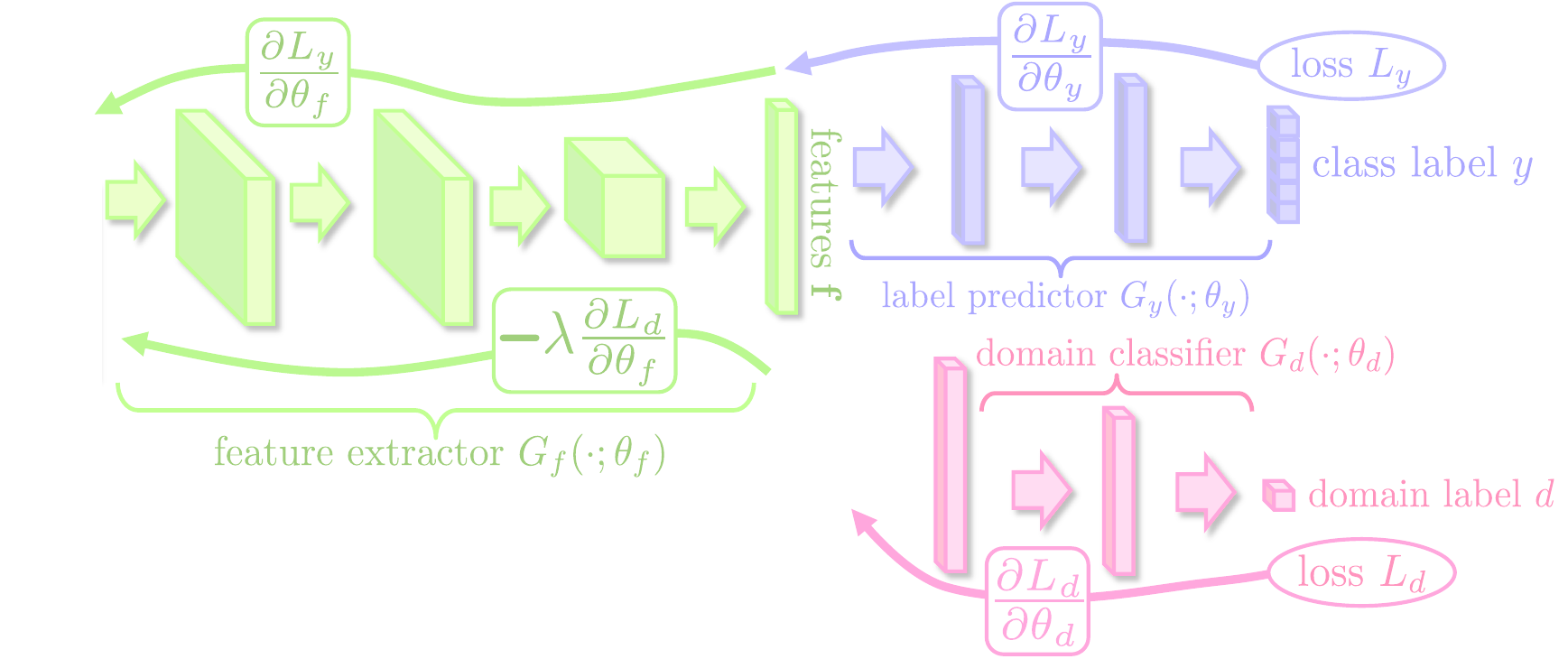
Validation of the selected methods
Measure of discrepancy: A-distance
* [A-distance](https://papers.nips.cc/paper_files/paper/2006/file/b1b0432ceafb0ce714426e9114852ac7-Paper.pdf): measure of discrepancy between distributions * Computed by minimizing the empirical risk of a classifier that discriminates between instances drawn from Source and Target
Measure of discrepancy: A-distance
* [A-distance](https://papers.nips.cc/paper_files/paper/2006/file/b1b0432ceafb0ce714426e9114852ac7-Paper.pdf): measure of discrepancy between distributions * Computed by minimizing the empirical risk of a classifier that discriminates between instances drawn from Source and Target
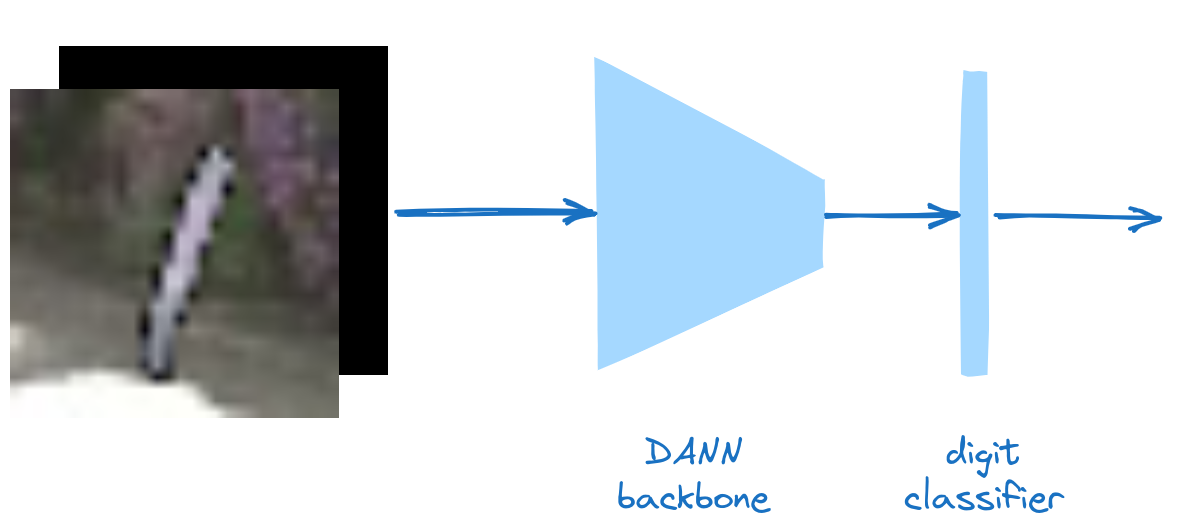
Measure of discrepancy: A-distance
Measure of discrepancy: A-distance
Measure of discrepancy: A-distance
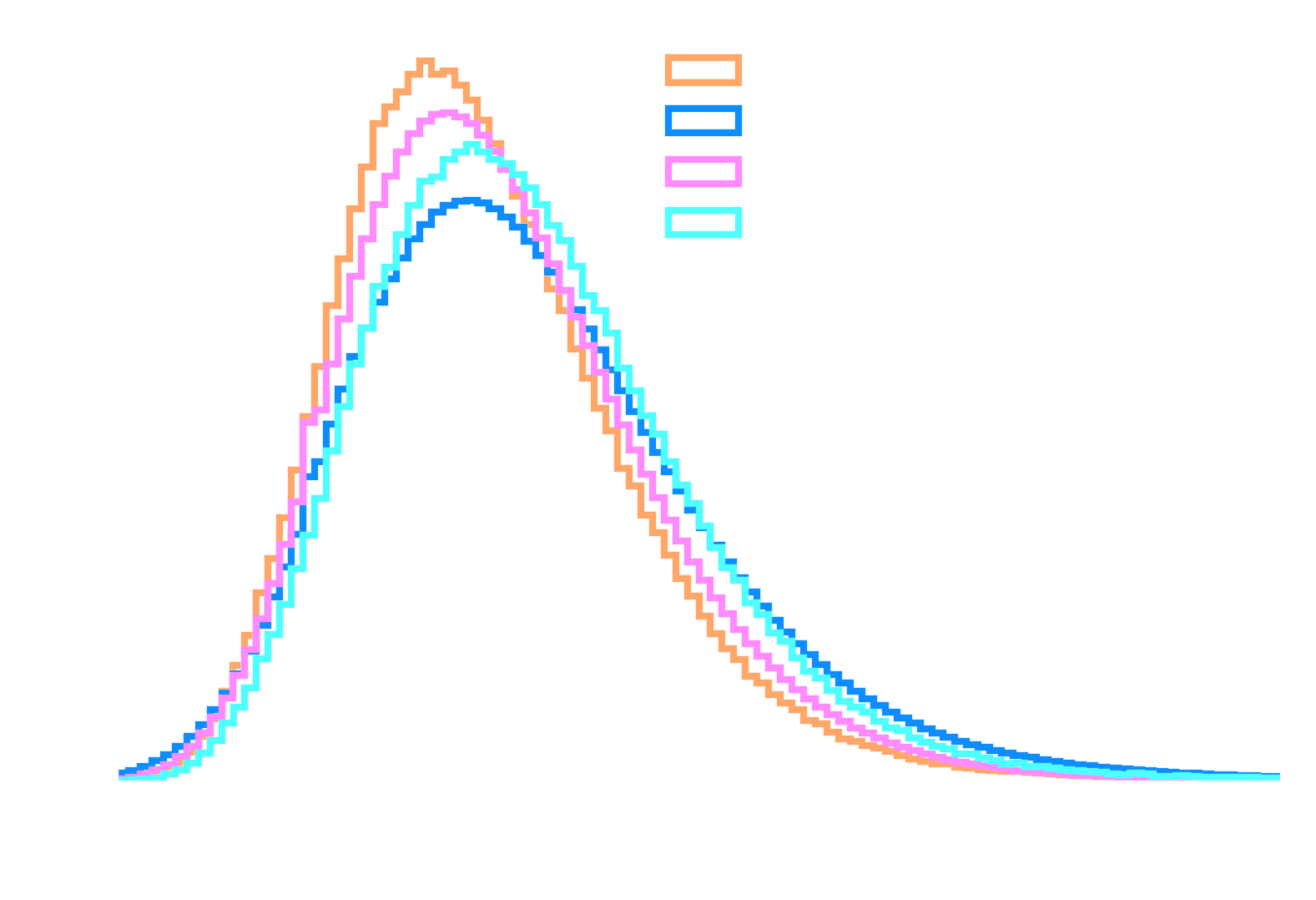
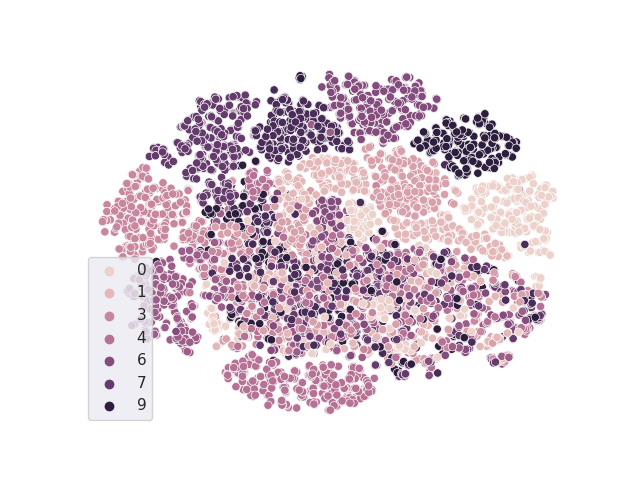
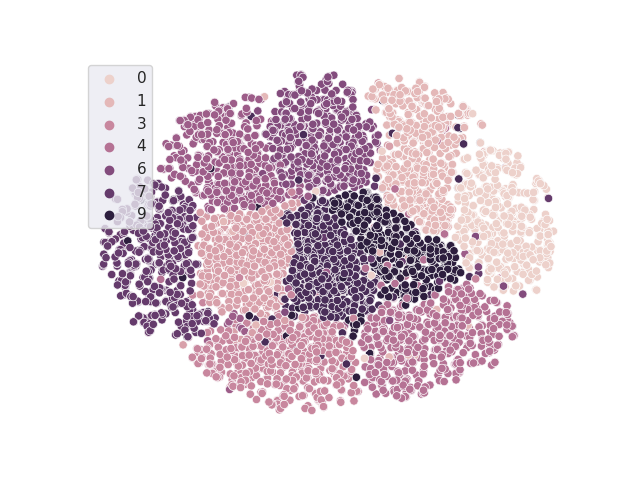
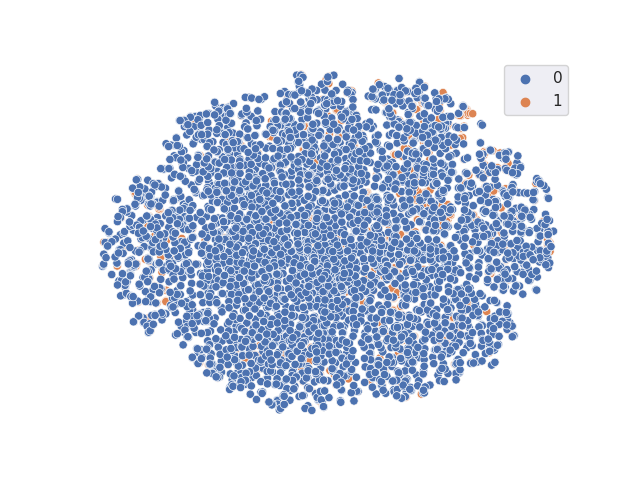
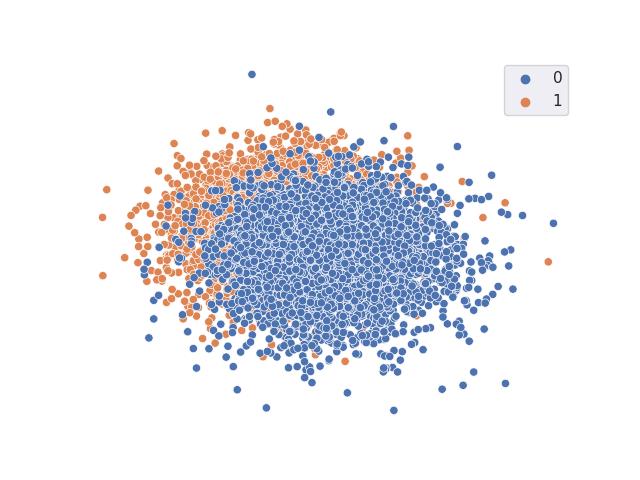
TSNE resulting from the classifier with freezed trained vanilla backbone
Accuracy = 0.9901123 A-distance = 1.9604492
Measure of discrepancy: A-distance
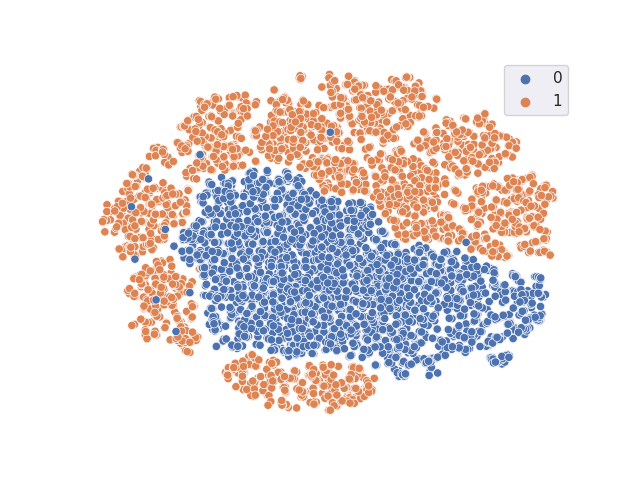
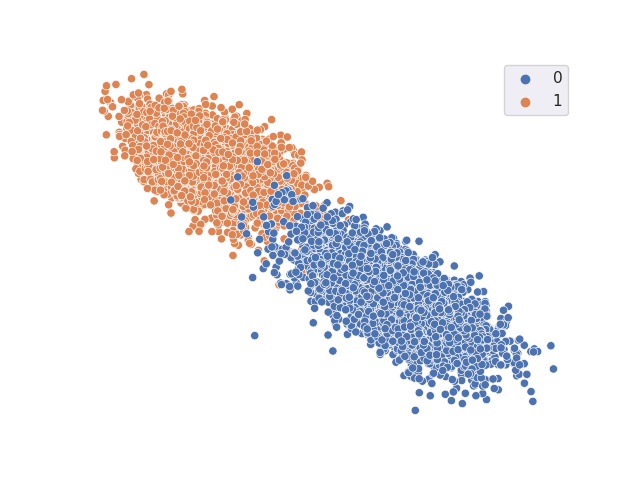
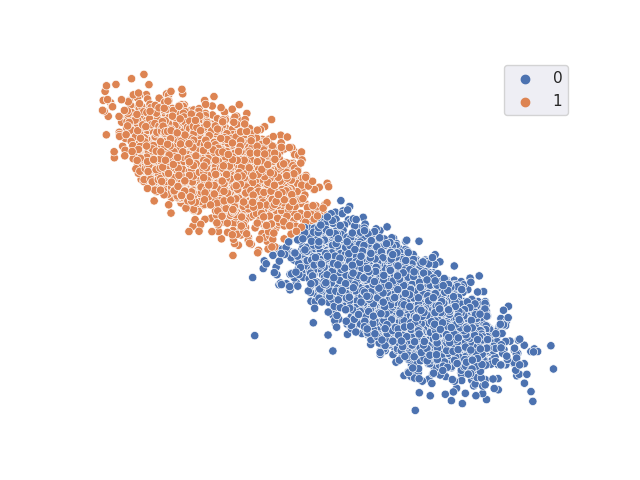
TSNE resulting from classifier with freezed trained DANN backbone
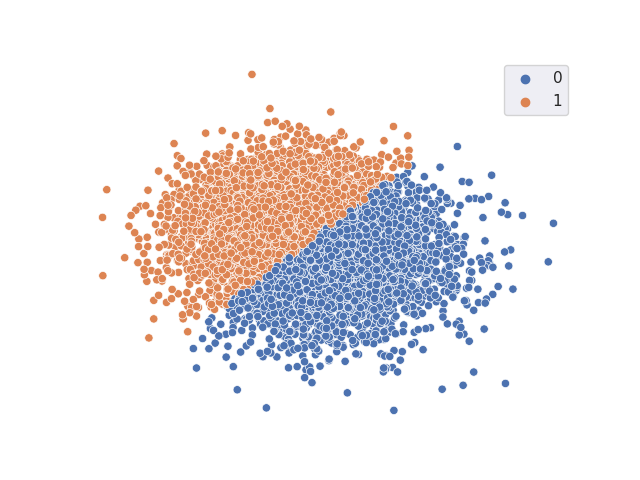
Accuracy = 0.7322998 A-distance = 0.9291992
Wrap-up
* Wide state-of-the-art * Selection, implementation and validation of four methods: * DANN * DeepJDOT * DeepCORAL * DAN * Integration of domain adaptation in the multi-task balancing * Application of the A-distance to the CTA simulations and real data
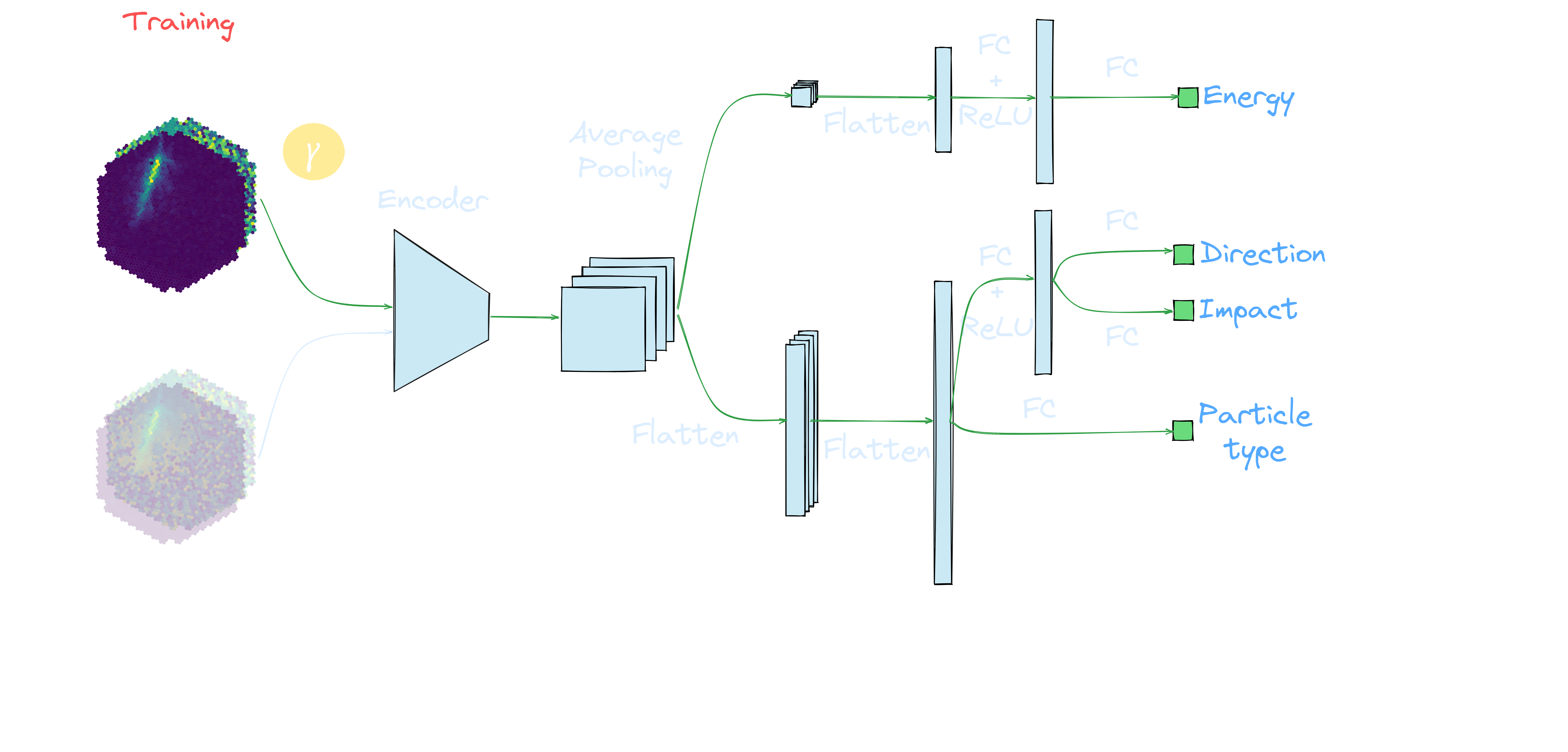
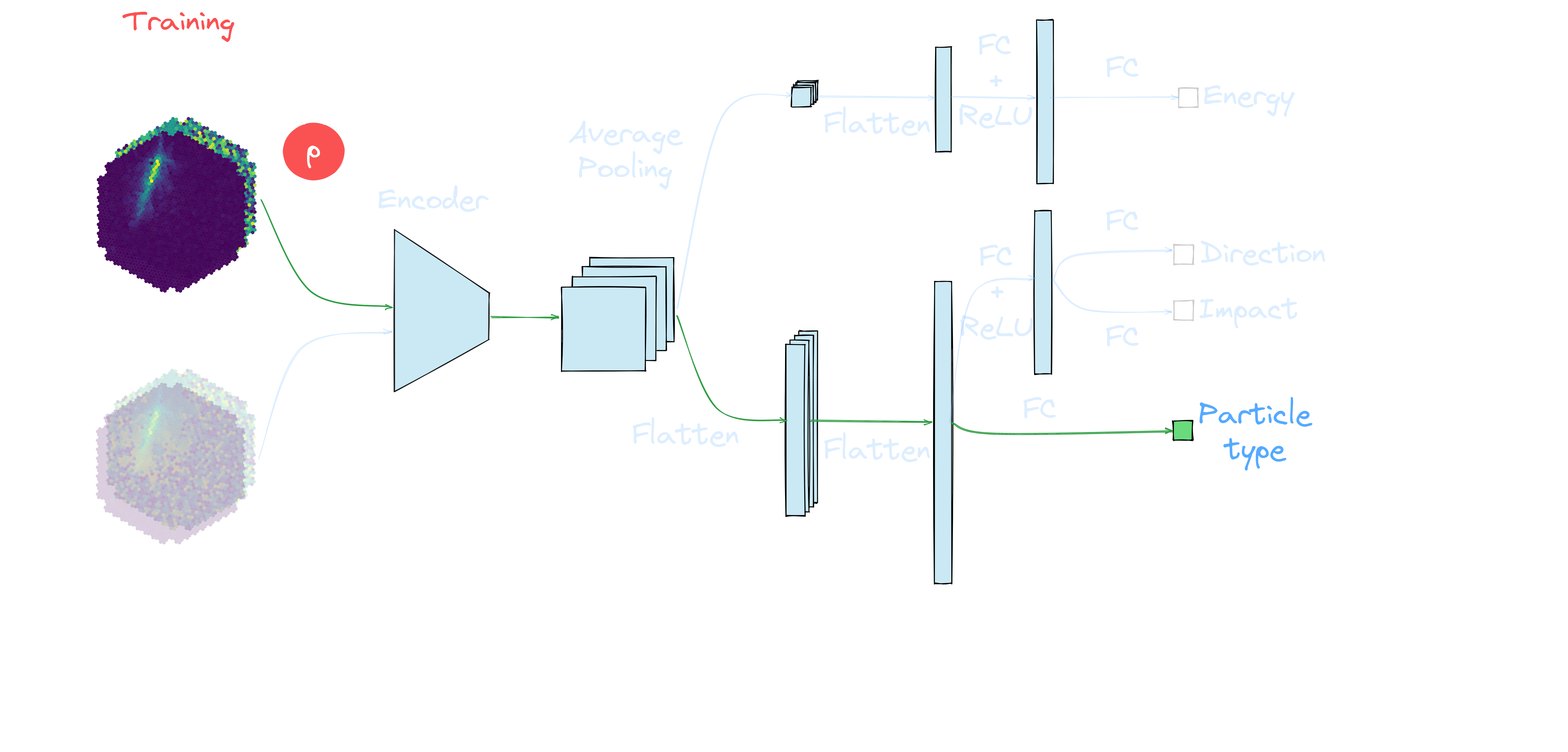
Setup
| prod5 trans80, alt=20deg, az=180deg | ||
|---|---|---|
Train |
Test |
|
| Source Labelled |
Target Unlabelled |
Unlabelled |
MC

|
MC+Poisson(0.4) (MC*)
|
MC+Poisson(0.4) (MC*)
 Use labels to characterize domain adaptation |
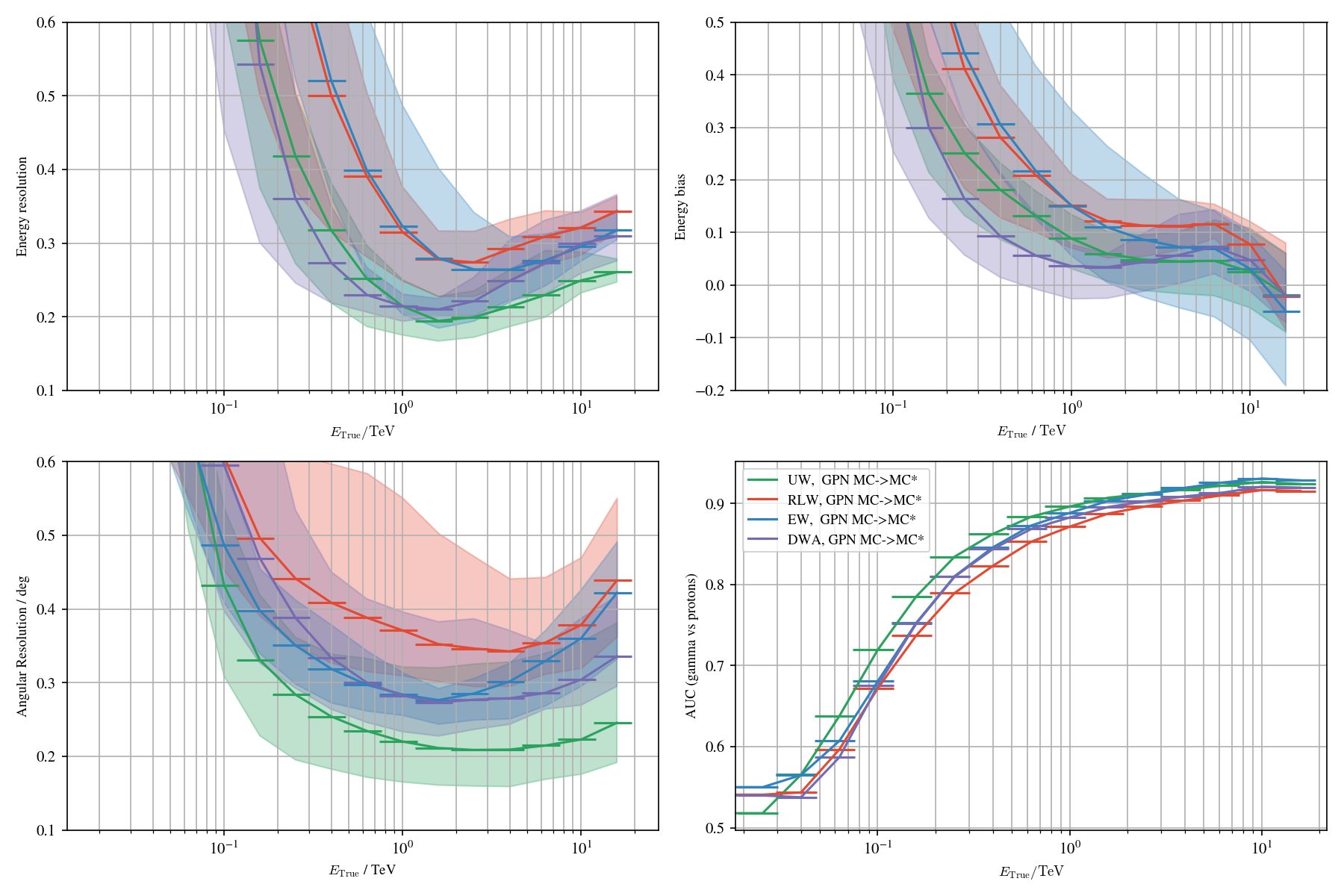
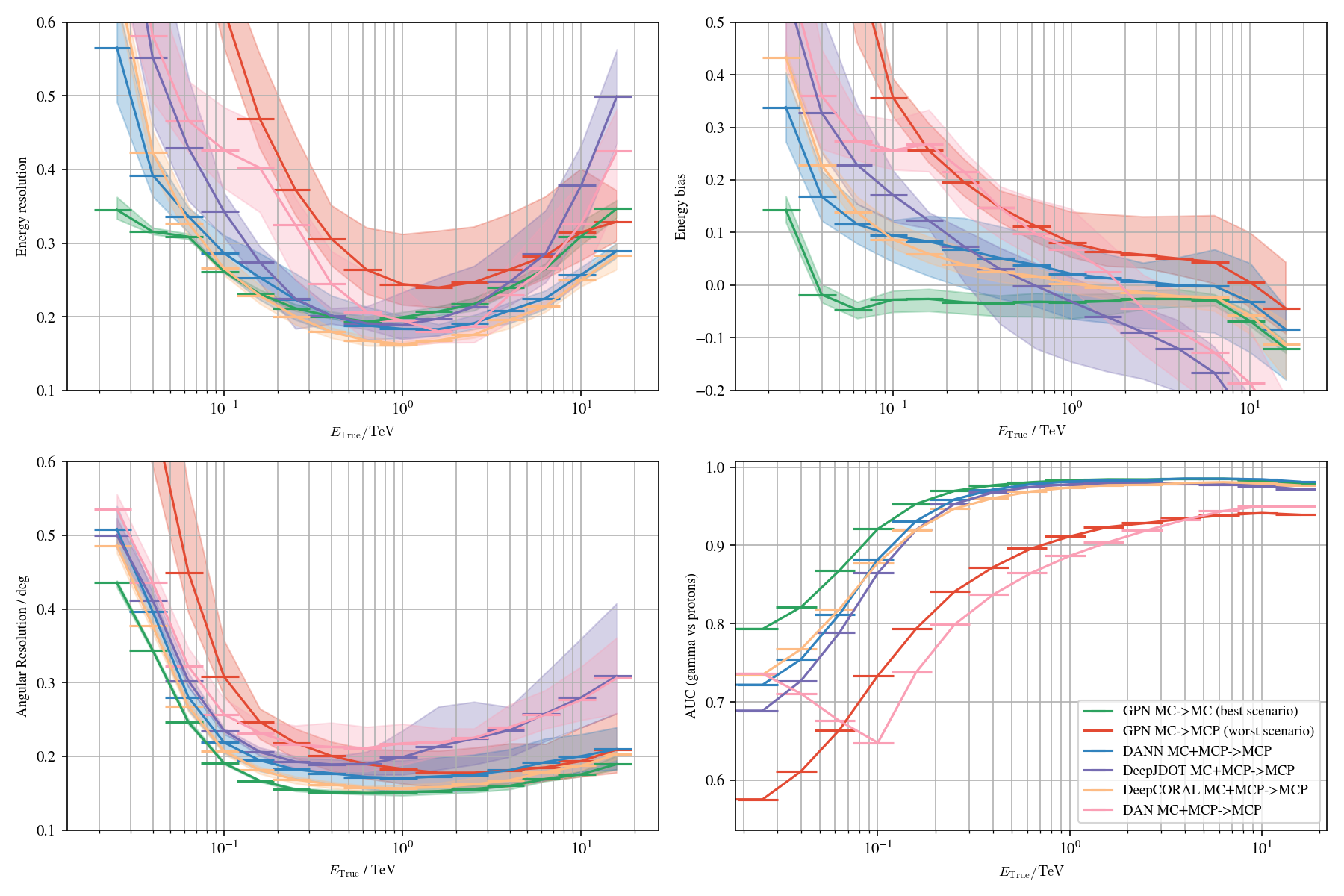
Application to MC: γ-PhysNet + DANN
Application to MC: γ-PhysNet + DANN
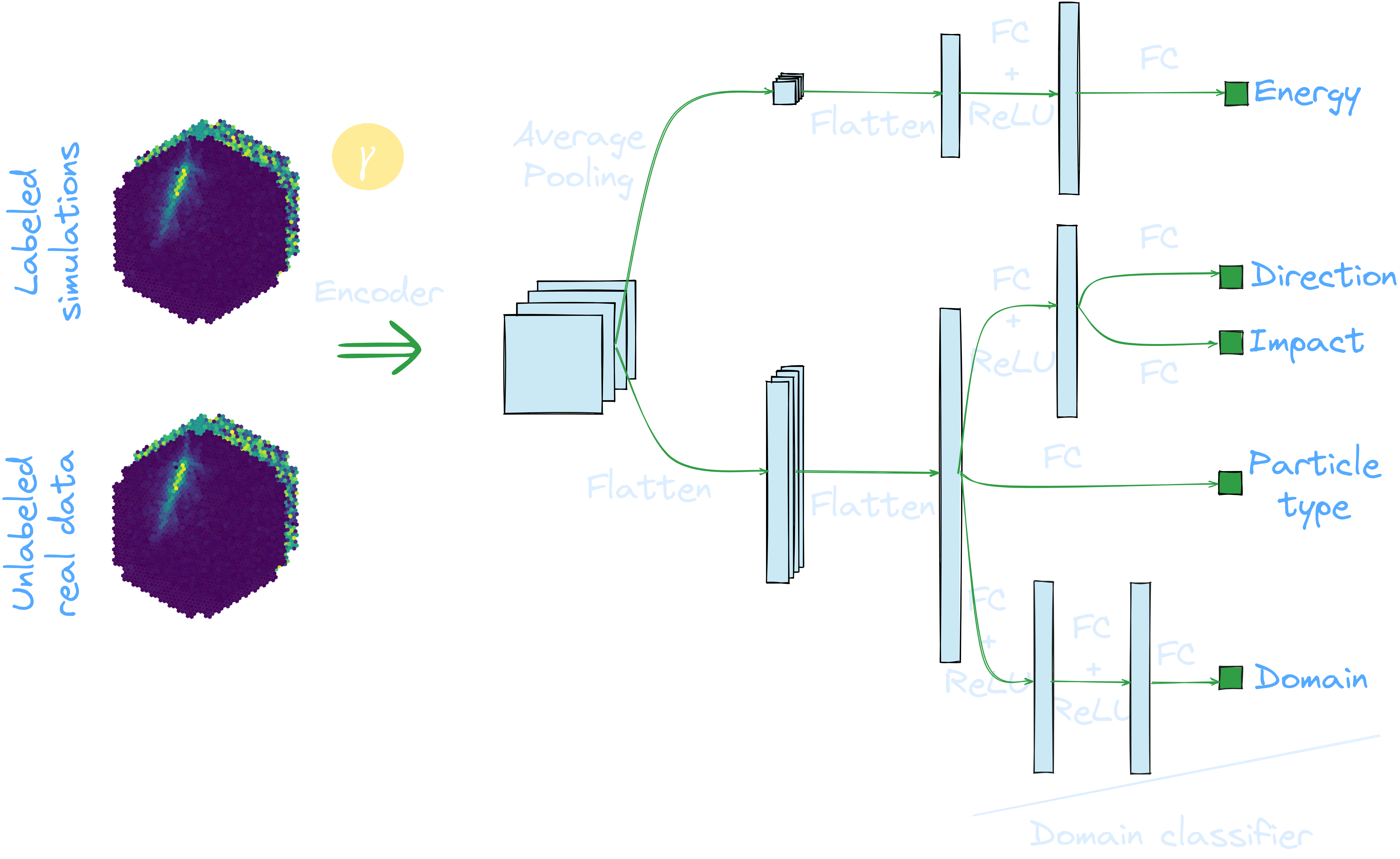
Application to MC: γ-PhysNet + DANN

Application to MC: γ-PhysNet + DANN
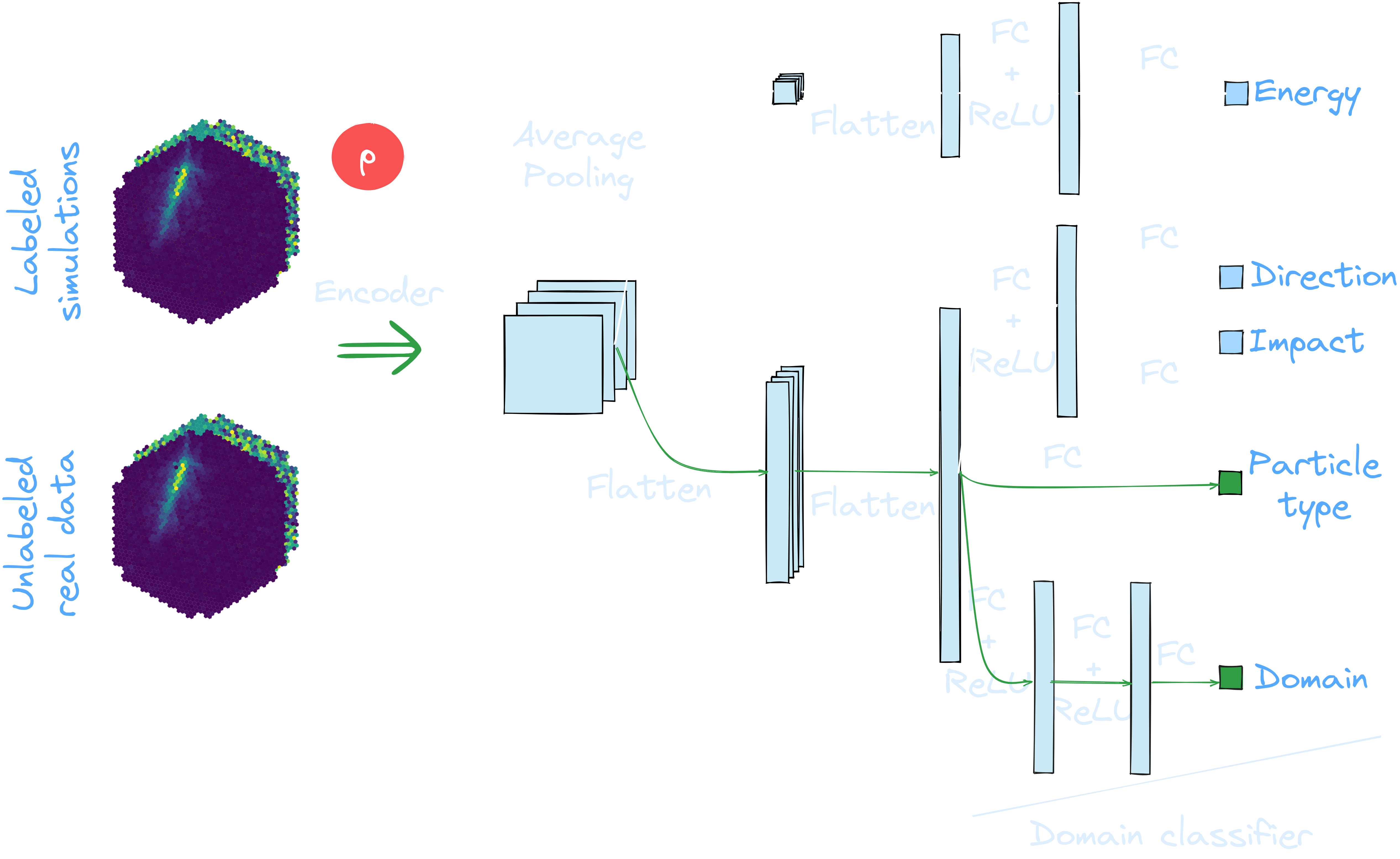
Application to MC: γ-PhysNet + DANN
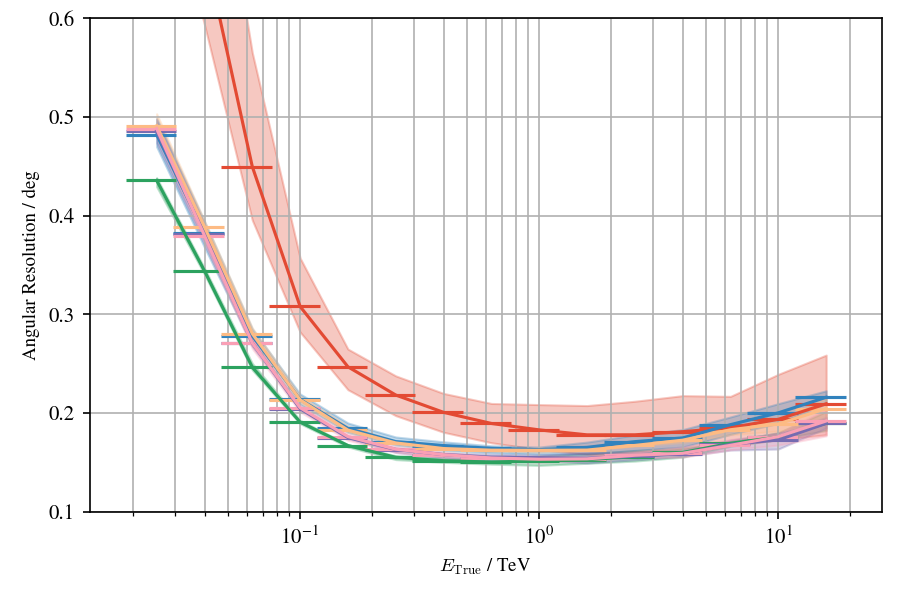
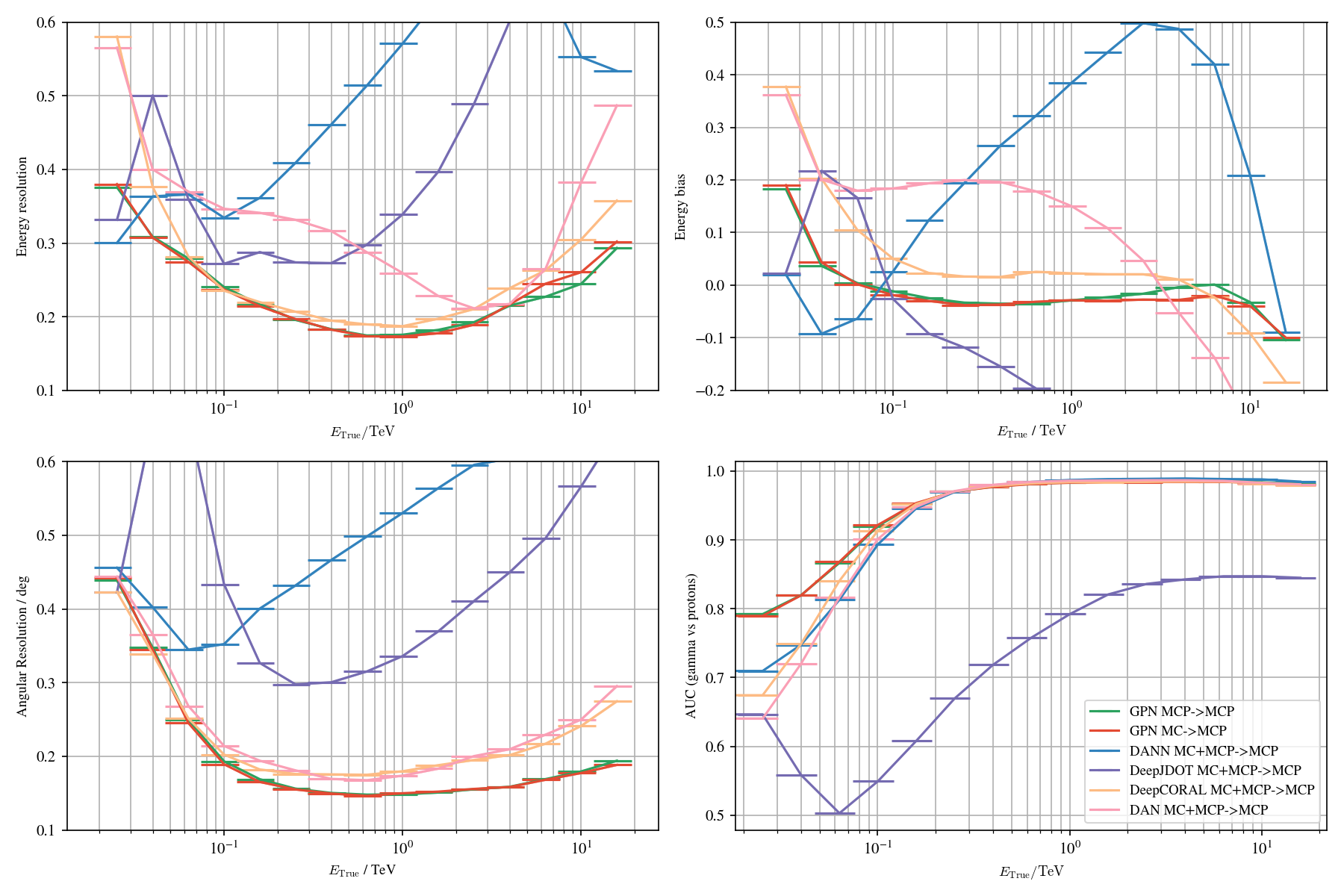
Application to MC
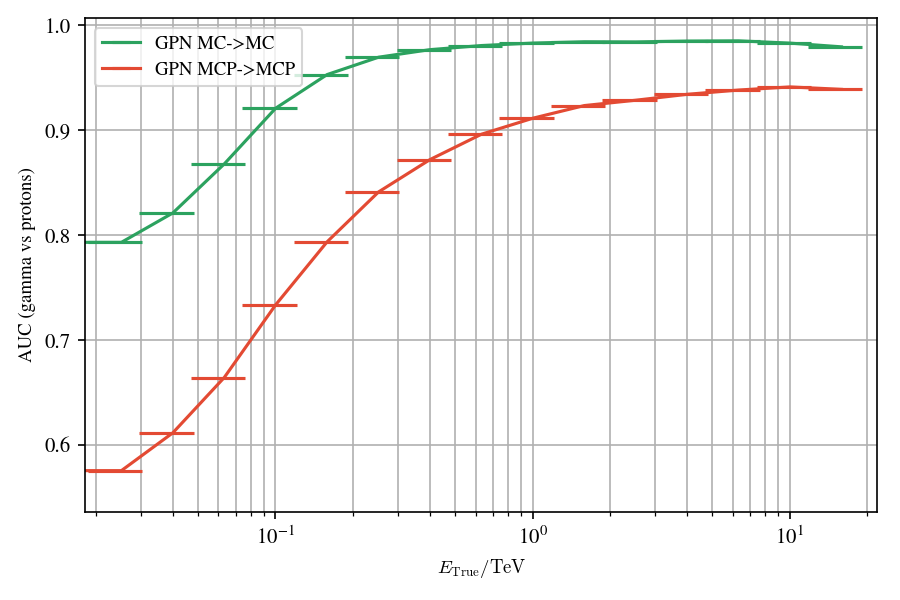
Application to MC
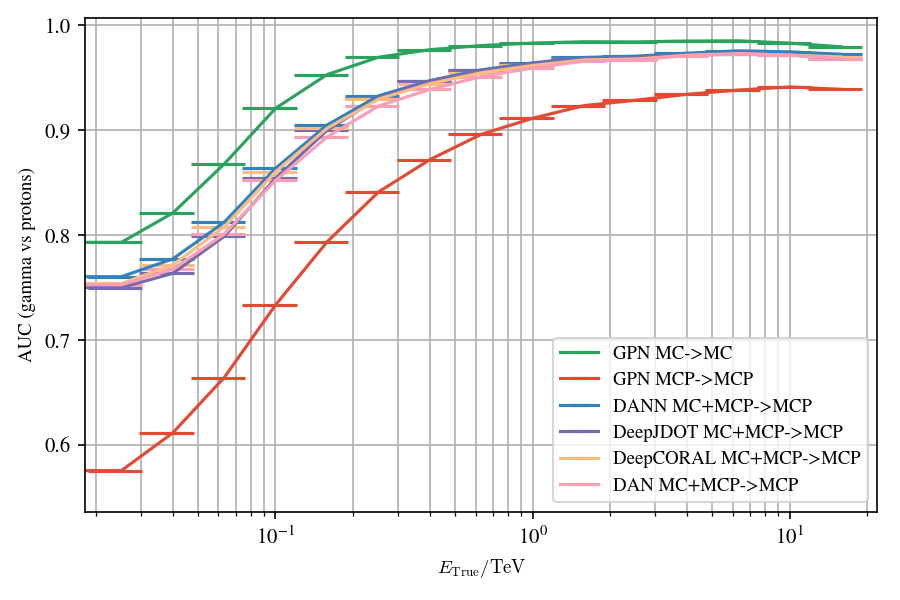
Application to MC
Application to MC
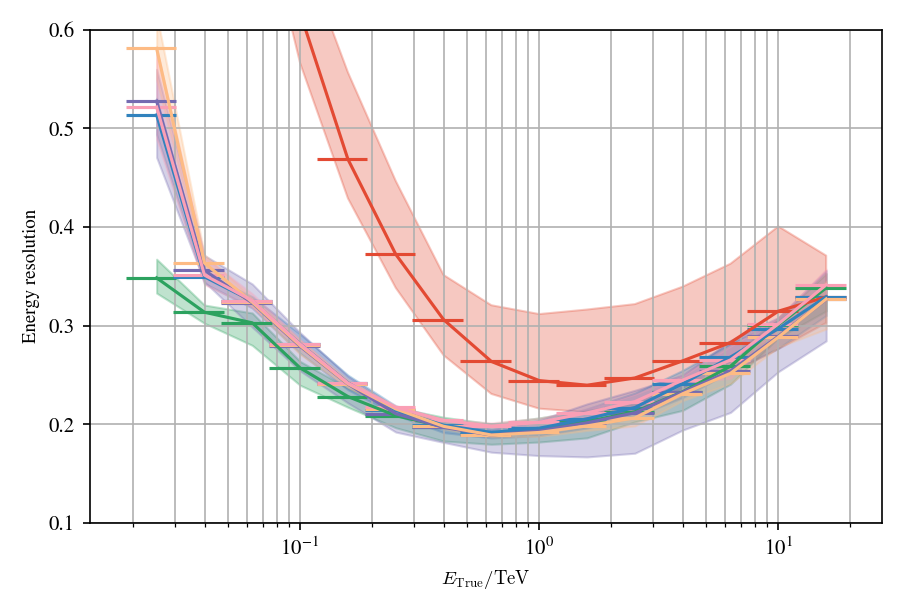
Application to MC
Application to MC
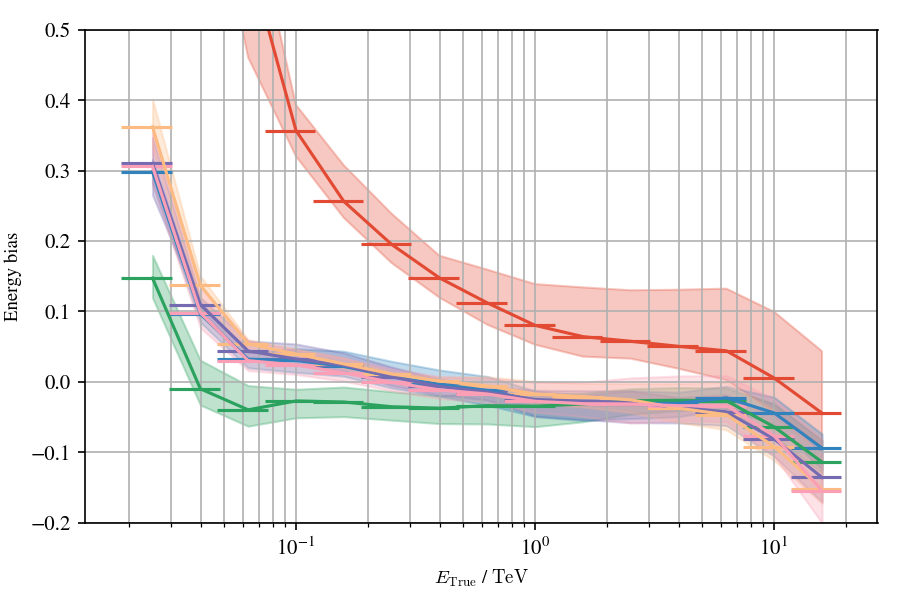
Application to MC
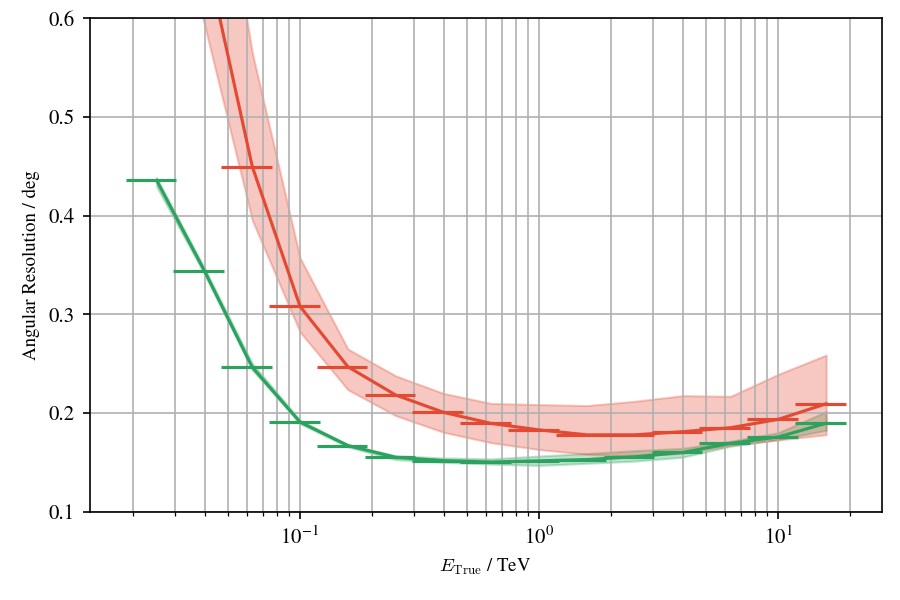
Application to MC
Loss balancing: worst scenario
Loss balancing: best scenario
Loss balancing: DANN
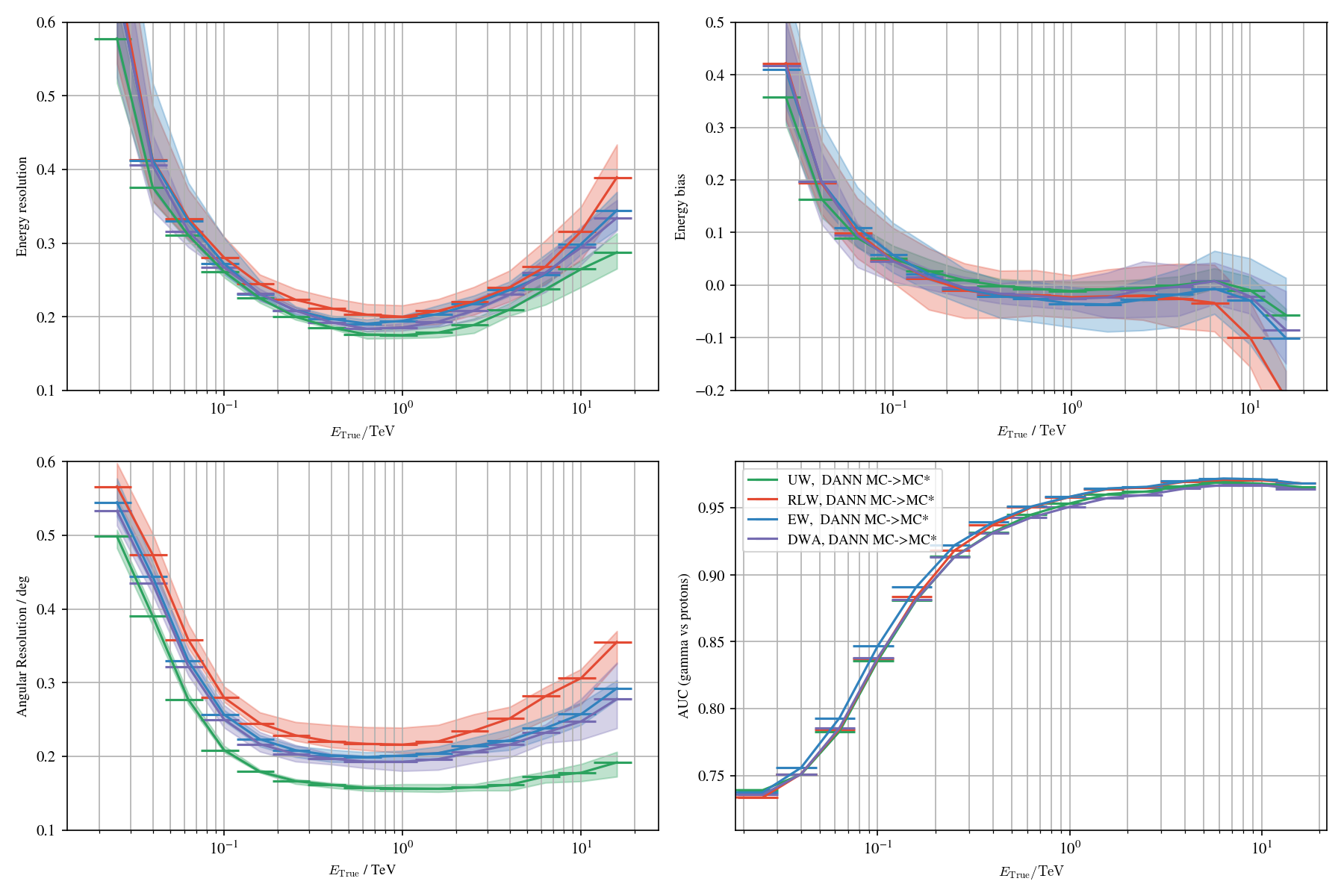
Label shifts
Wrap-up
* Domain adaptation successfully tackles the discrepencies on simulations * Don't take into account the label shifts between sources and targets * Results submitted and accepted in the [CBMI 2023 conference](https://cbmi2023.org/)
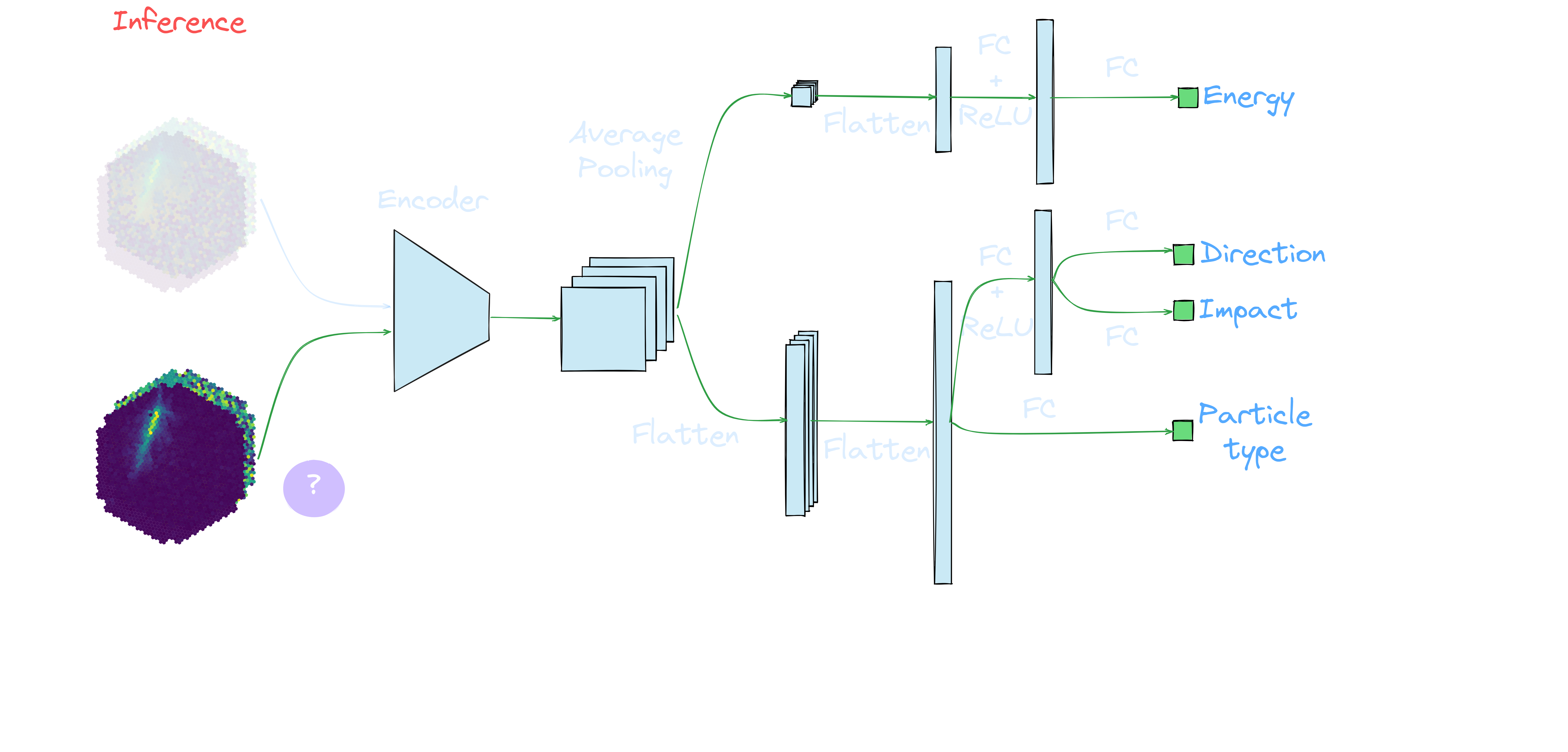
Domain adaptation applied to the Crab Nebula: Setup
| Crab Nebula 6894 & 6895 | ||
|---|---|---|
Train |
Test |
|
| Source Labelled |
Target Unlabelled |
Unlabelled |
|
MC+Poisson (MC*)
ratio=50%/50% |
Real data ratio=1γ for > 1000p |
Real data |
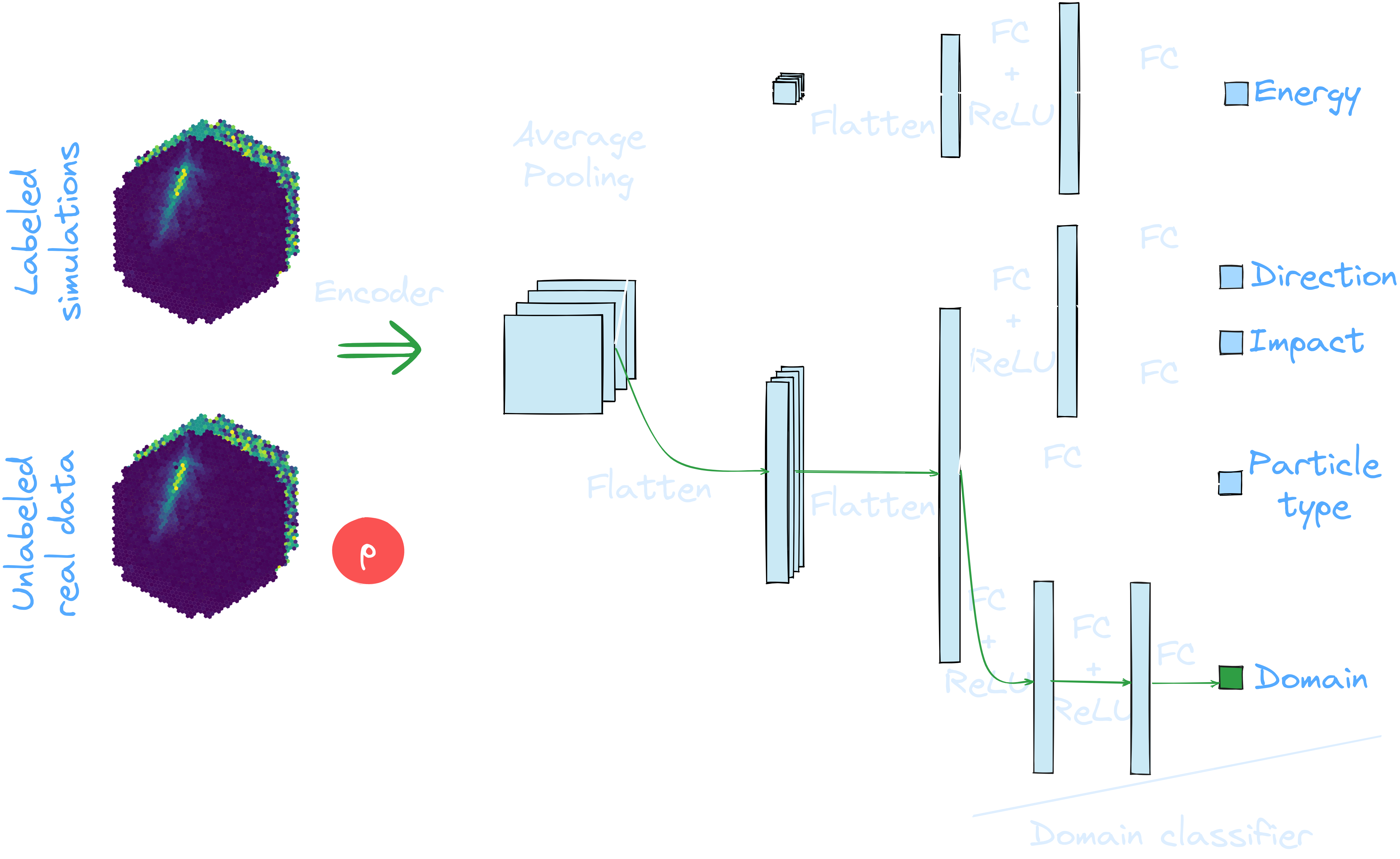
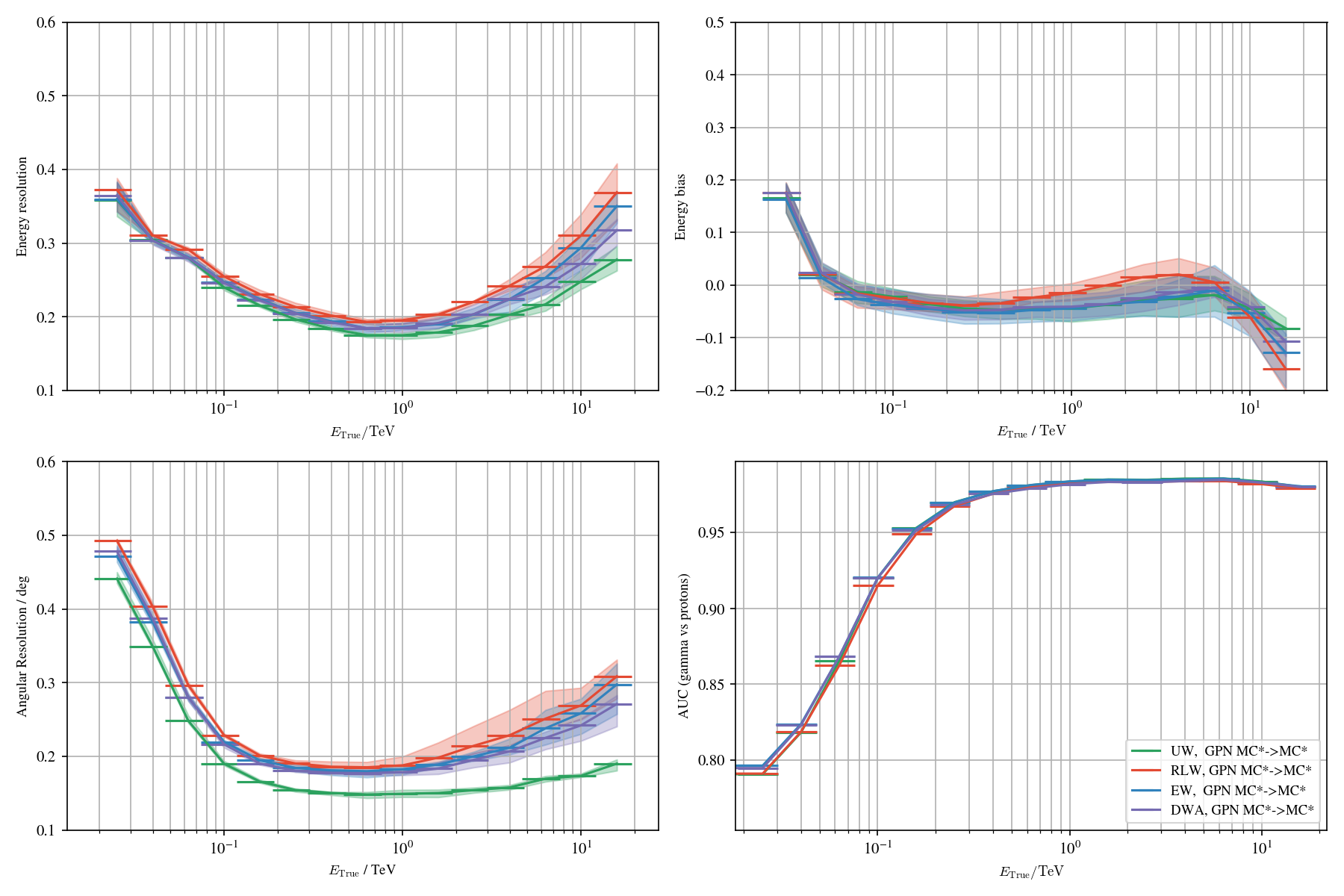
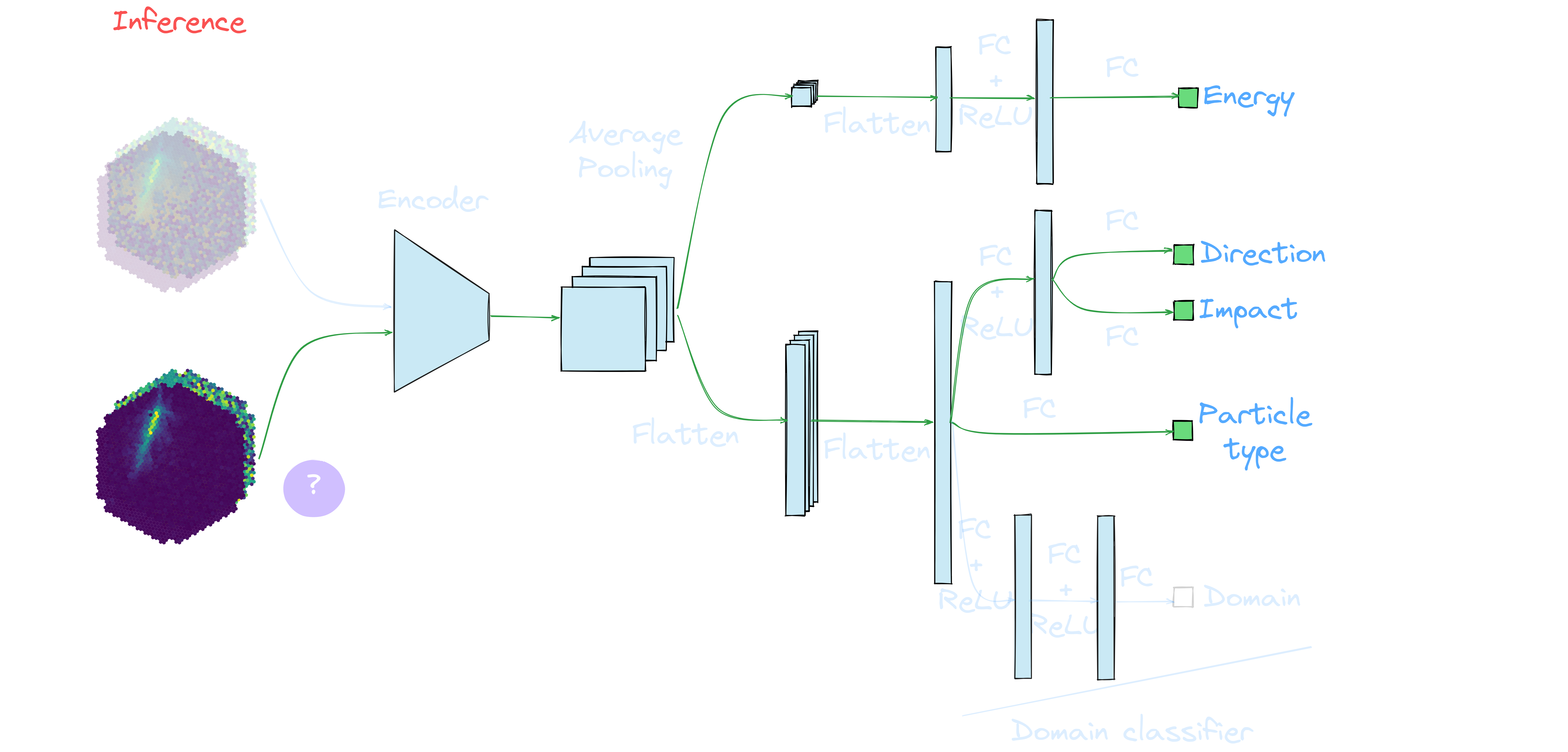
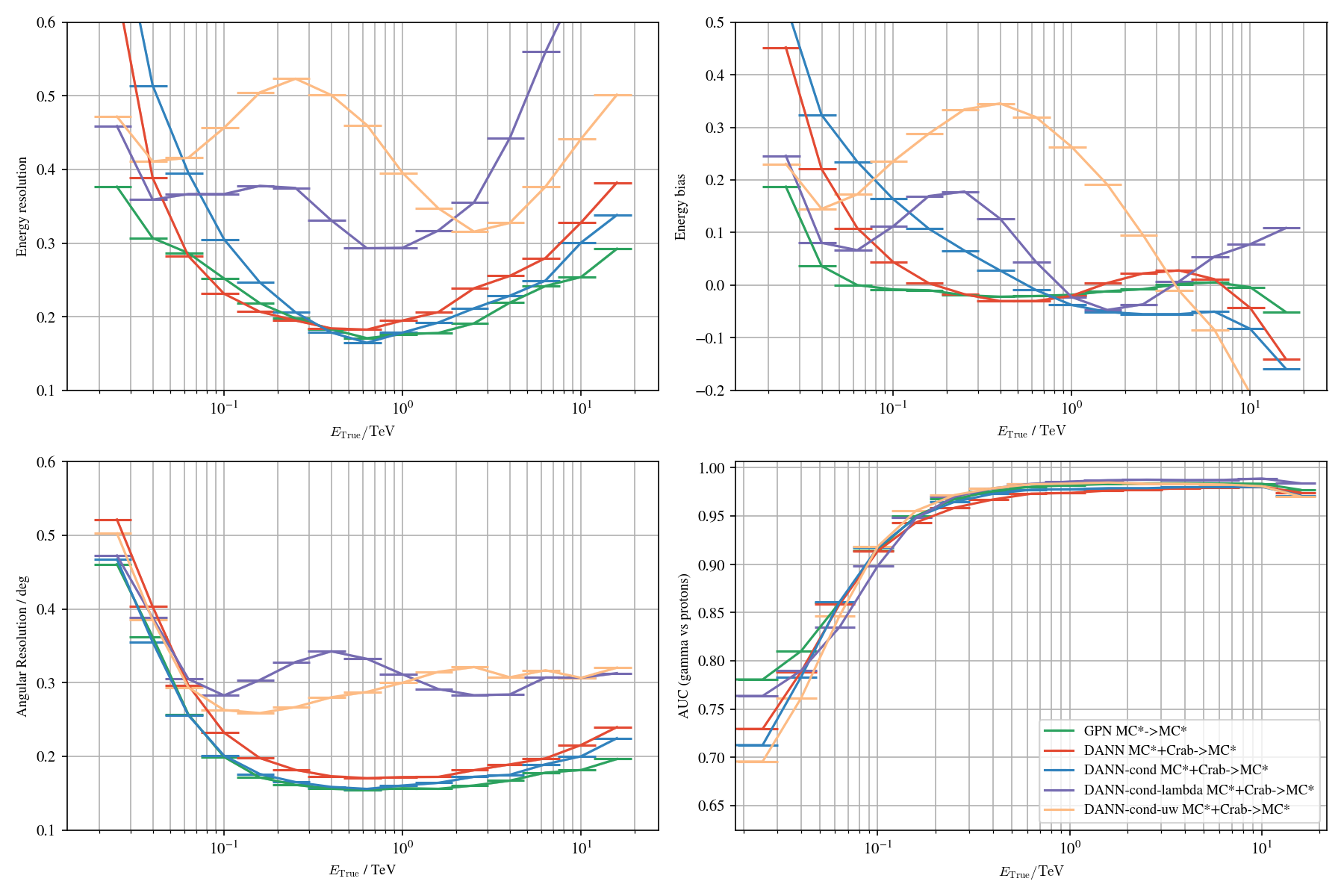
Application to real data: γ-PhysNet + DANN conditional
Application to real data: γ-PhysNet + DANN conditional
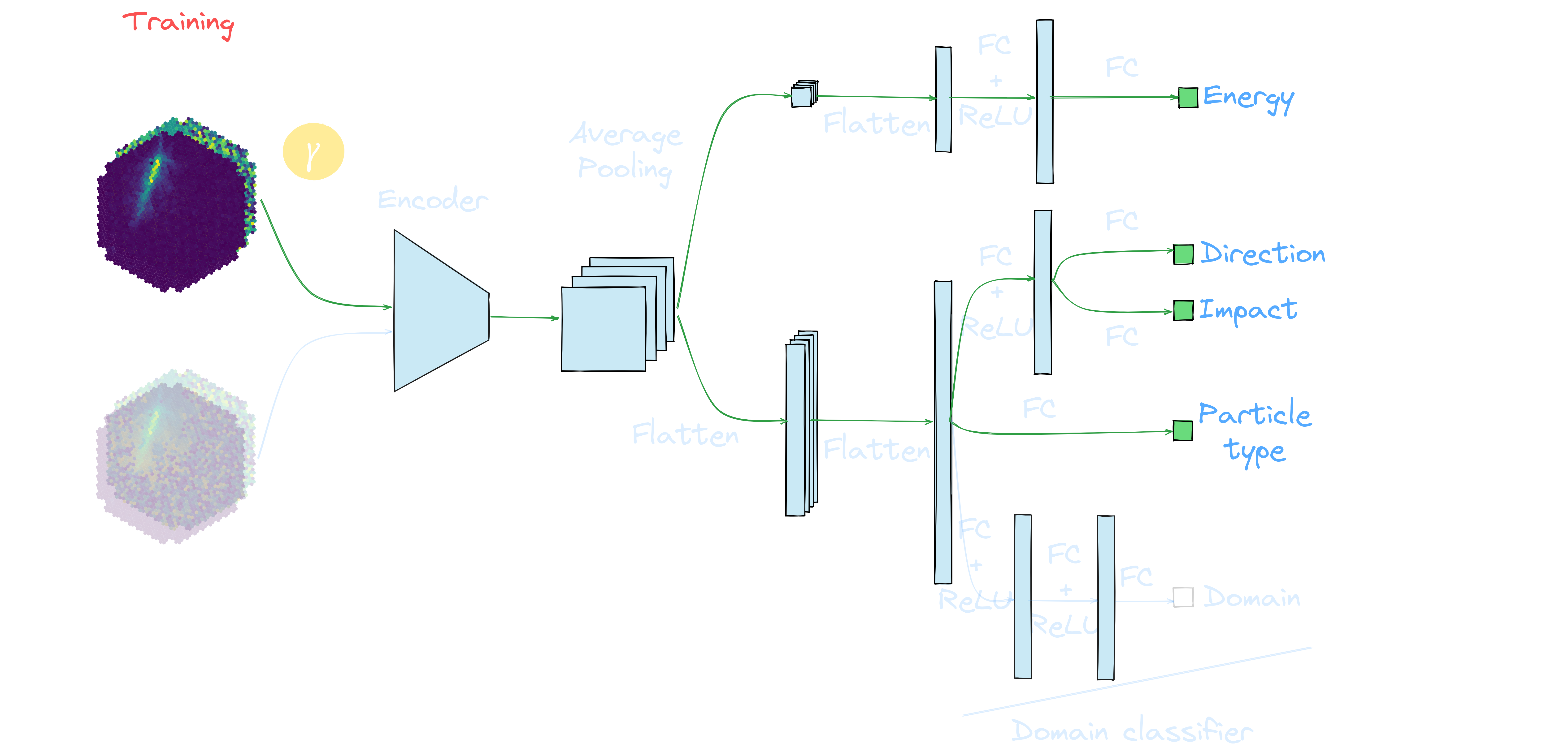
Application to real data: γ-PhysNet + DANN conditional
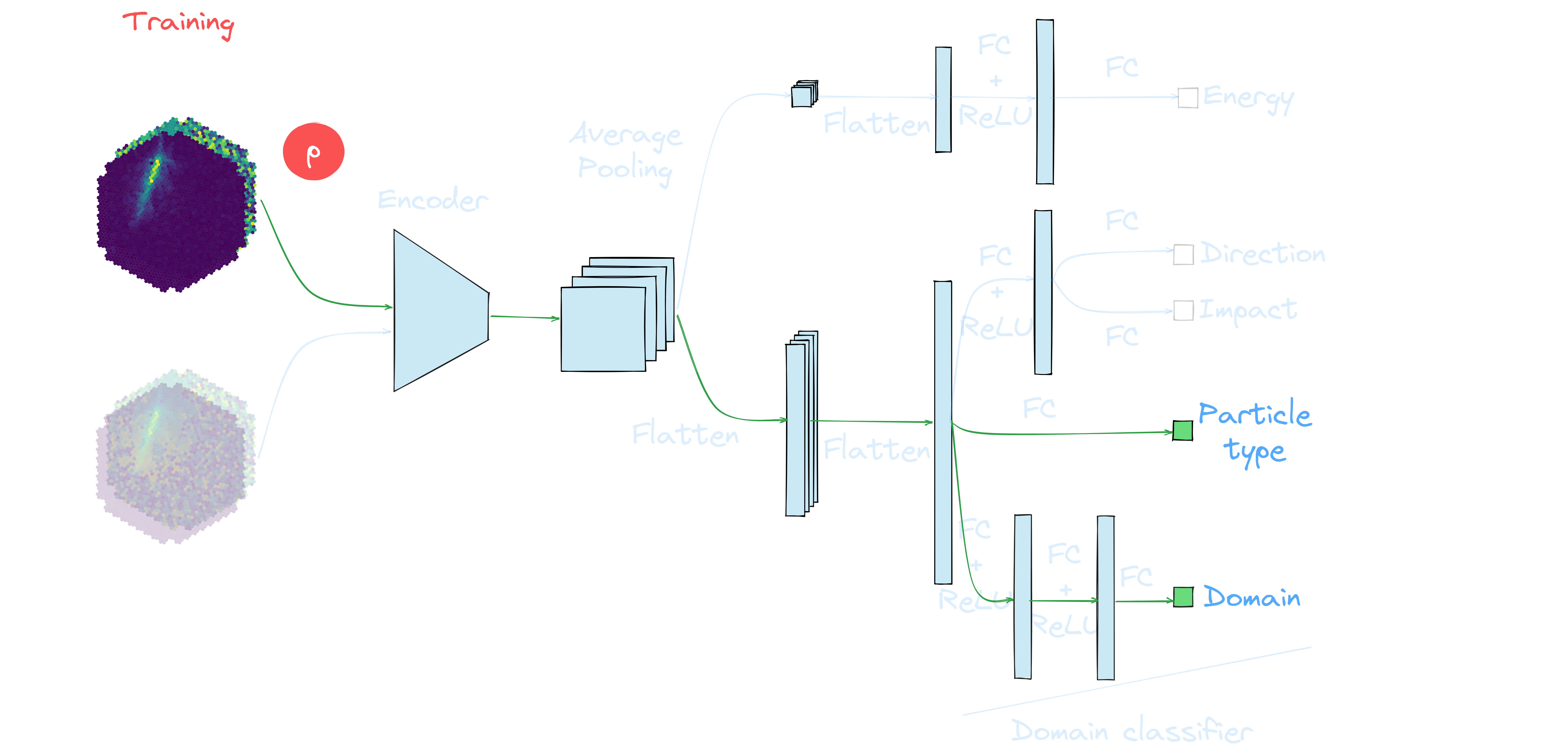
Application to real data: γ-PhysNet + DANN conditional
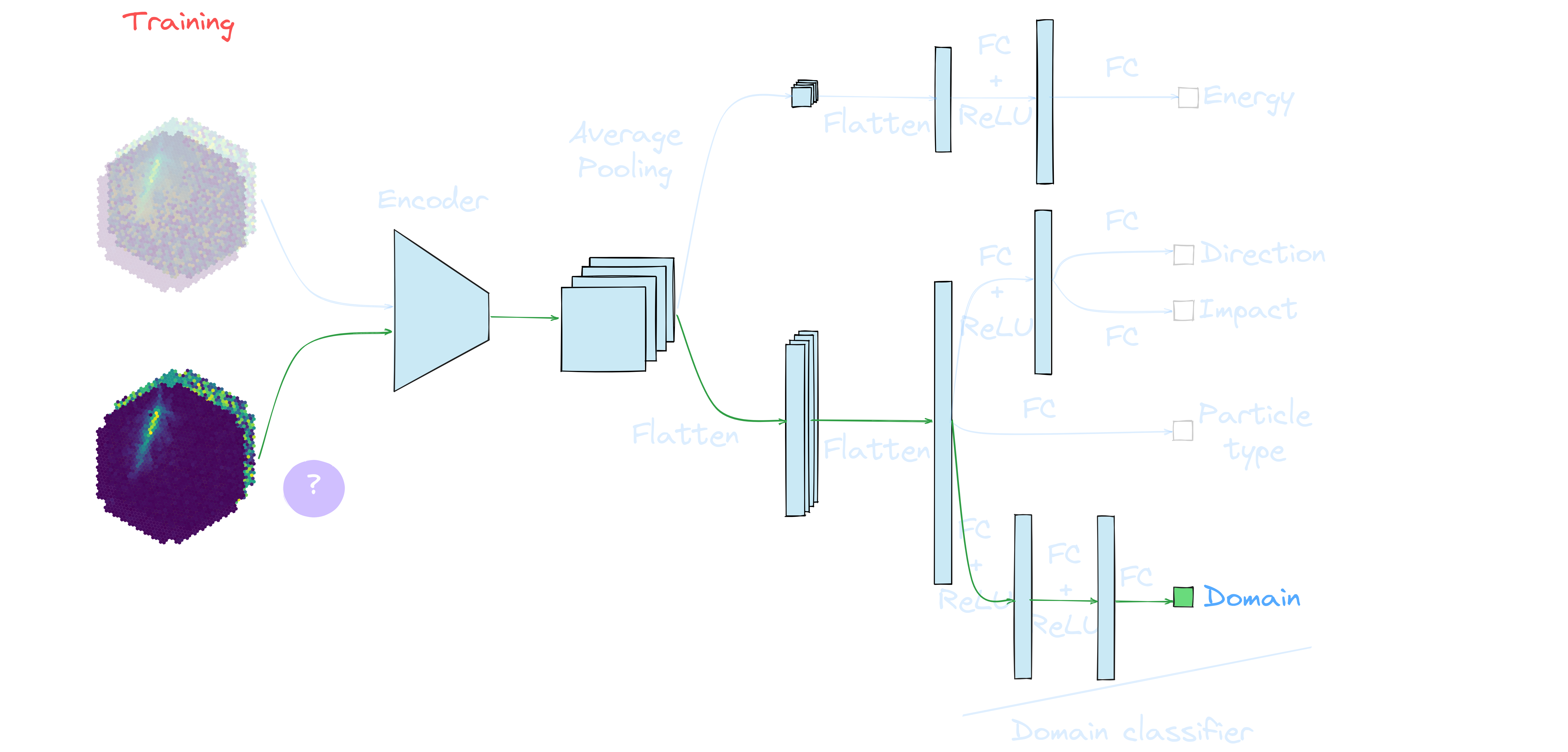
Application to real data: γ-PhysNet + DANN conditional
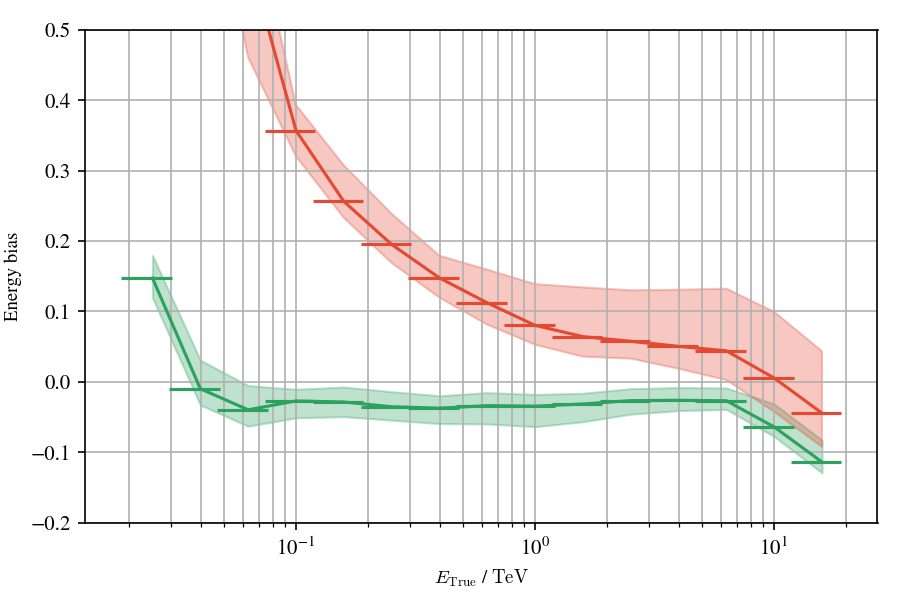
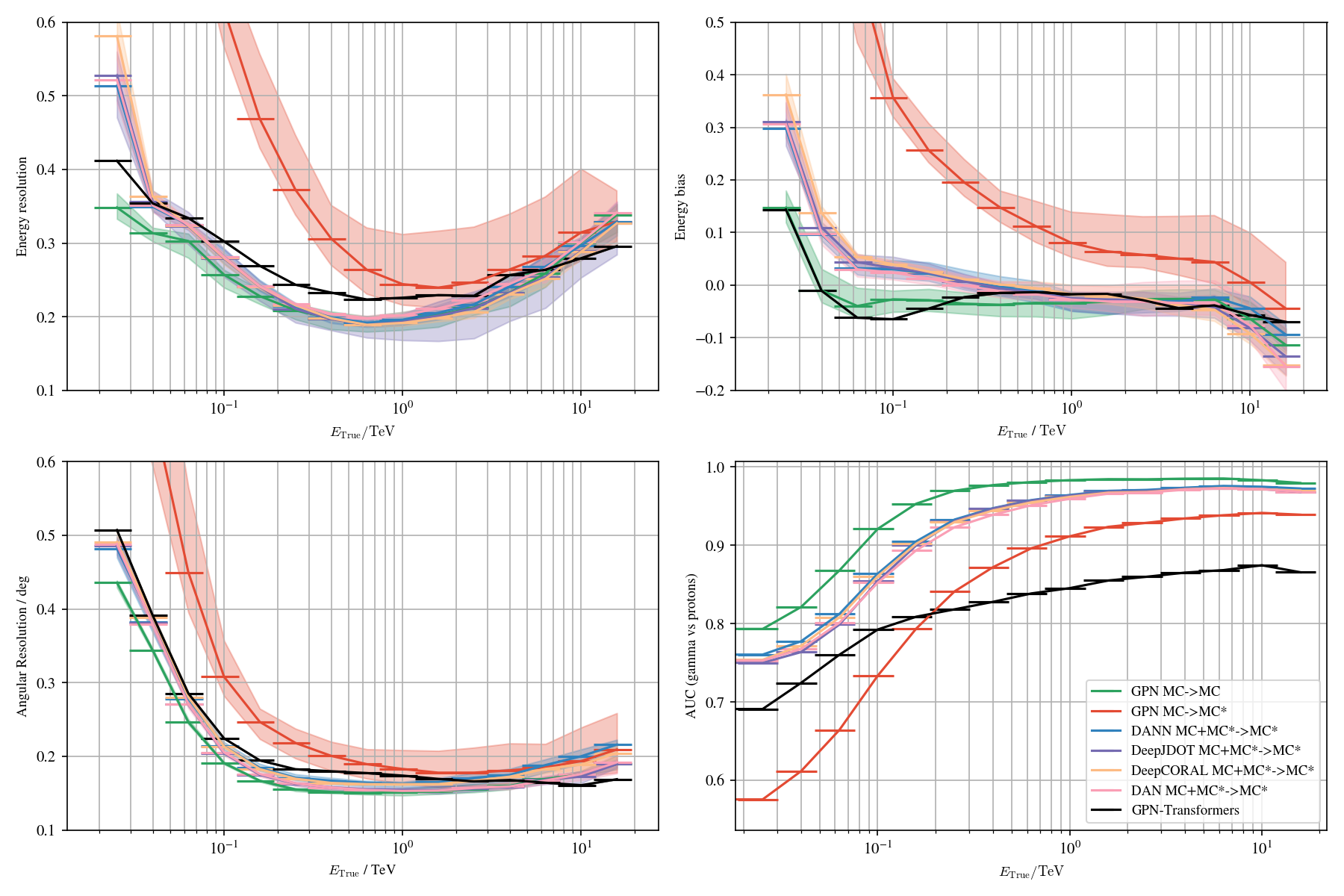
Domain adaptation applied to the Crab Nebula: Results
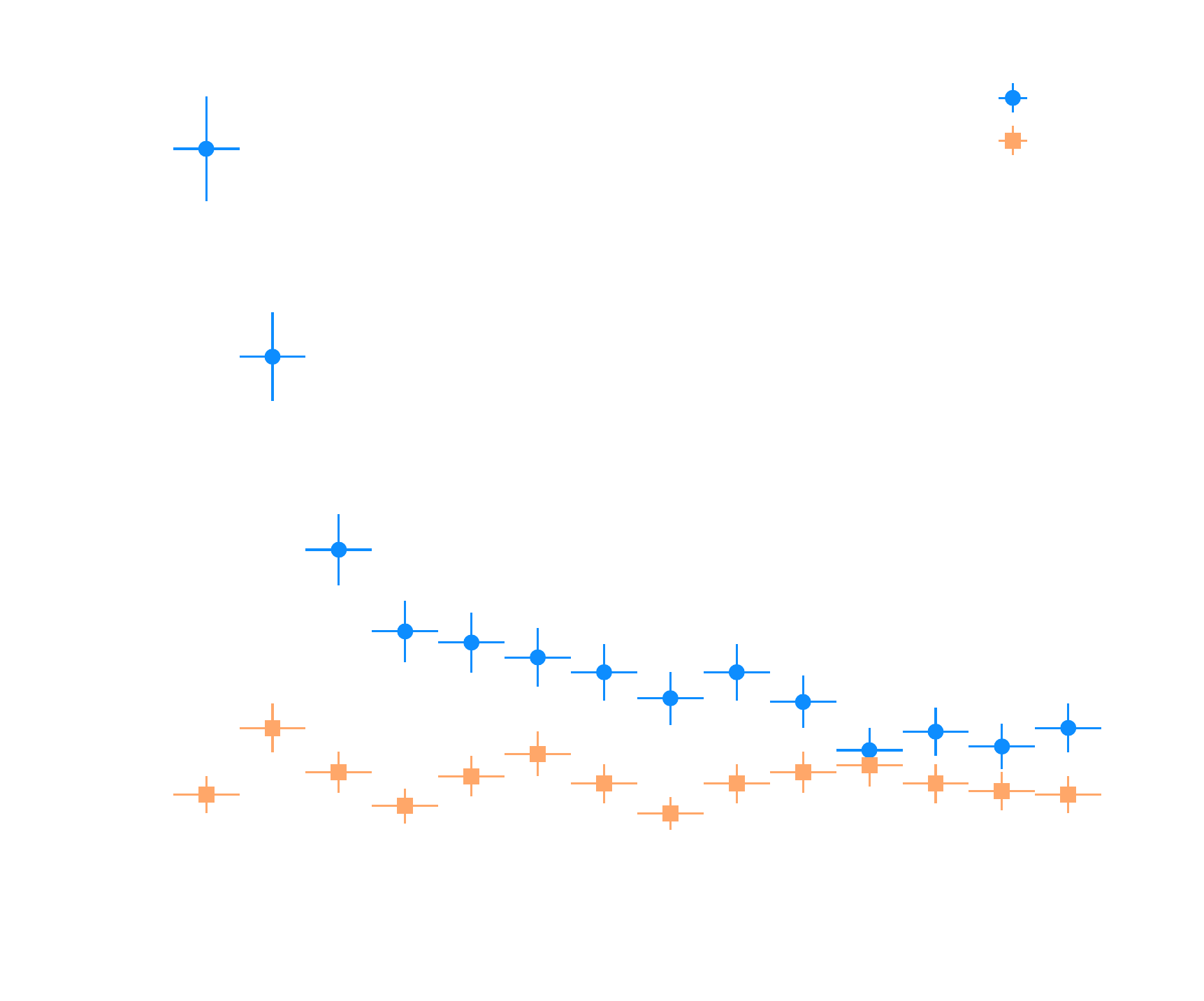
Correction of label shifts
Integration of domain adaptation in multi-loss balancing
More specifically for DANN
Wrap-up
* Number of excess gammas decreasing but improved significance σ compared to standard analysis * Tested on training data MC*, will be tested on MC * Domain shift problem between MC and real data: * DANN conditional * MC Gamma injection in real targets * Domain adaptation and multi-loss balancing in the context of real data not functional * More sources will be tested
Vision Transformers
* First developped for NLP, then introduced in CV applications * CNN: Translation invariance and locality * Vision Transformers (ViT): * Rely on attention mechanisms * Suffer from inductive bias * Training on large datasets (14M-300M images) surpasses inductive biase * Masked Auto-Encoder (MAE): * Used as pre-training to foster generalization * Images suffer from spatial redundancy * A very high masking ratio is applied (75%) * Then: fine-tune
Vision Transformers
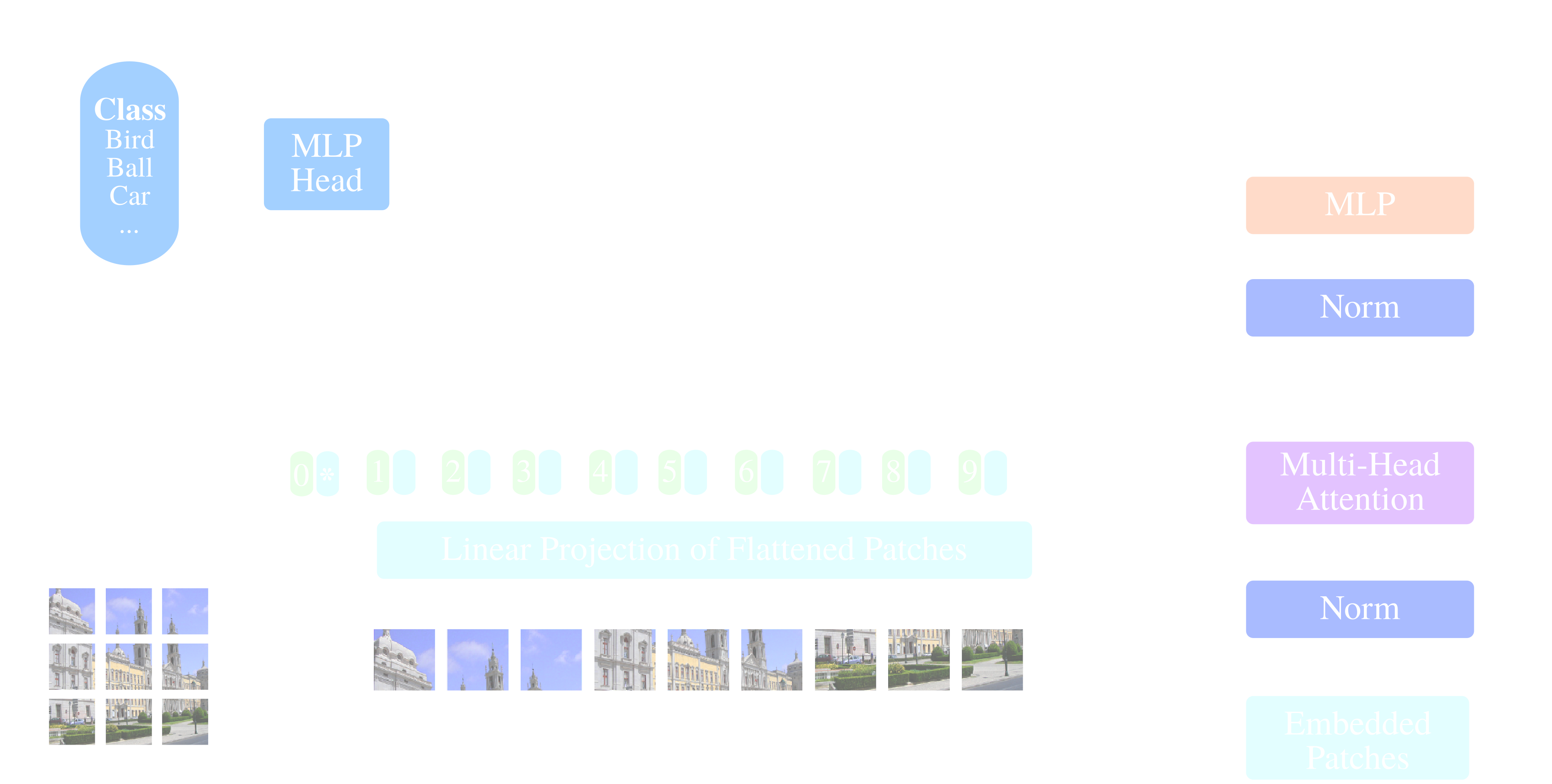
Masked auto-encoder architecture
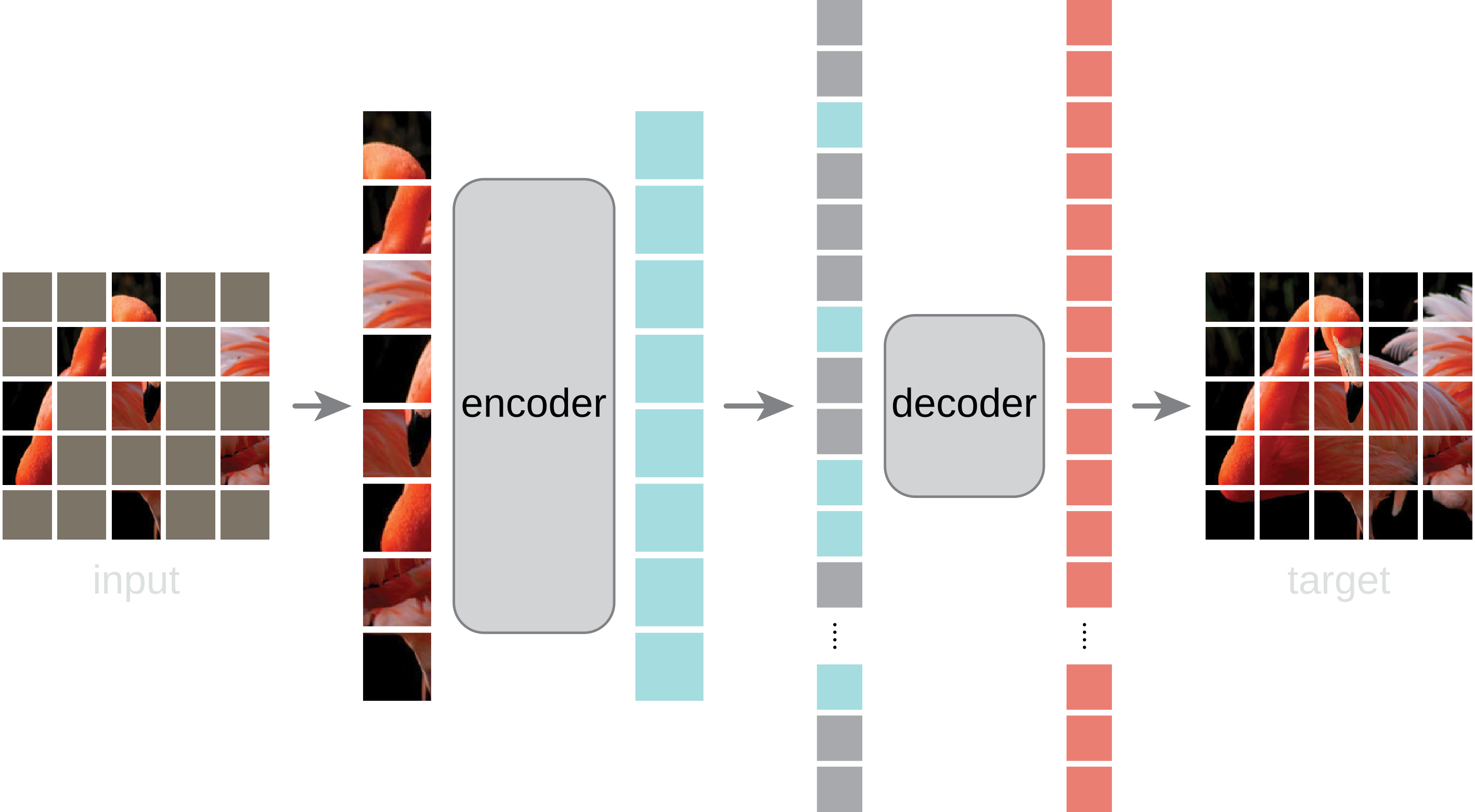
Application of MAE to LST images
MAE

MAE

MAE

MAE

MAE

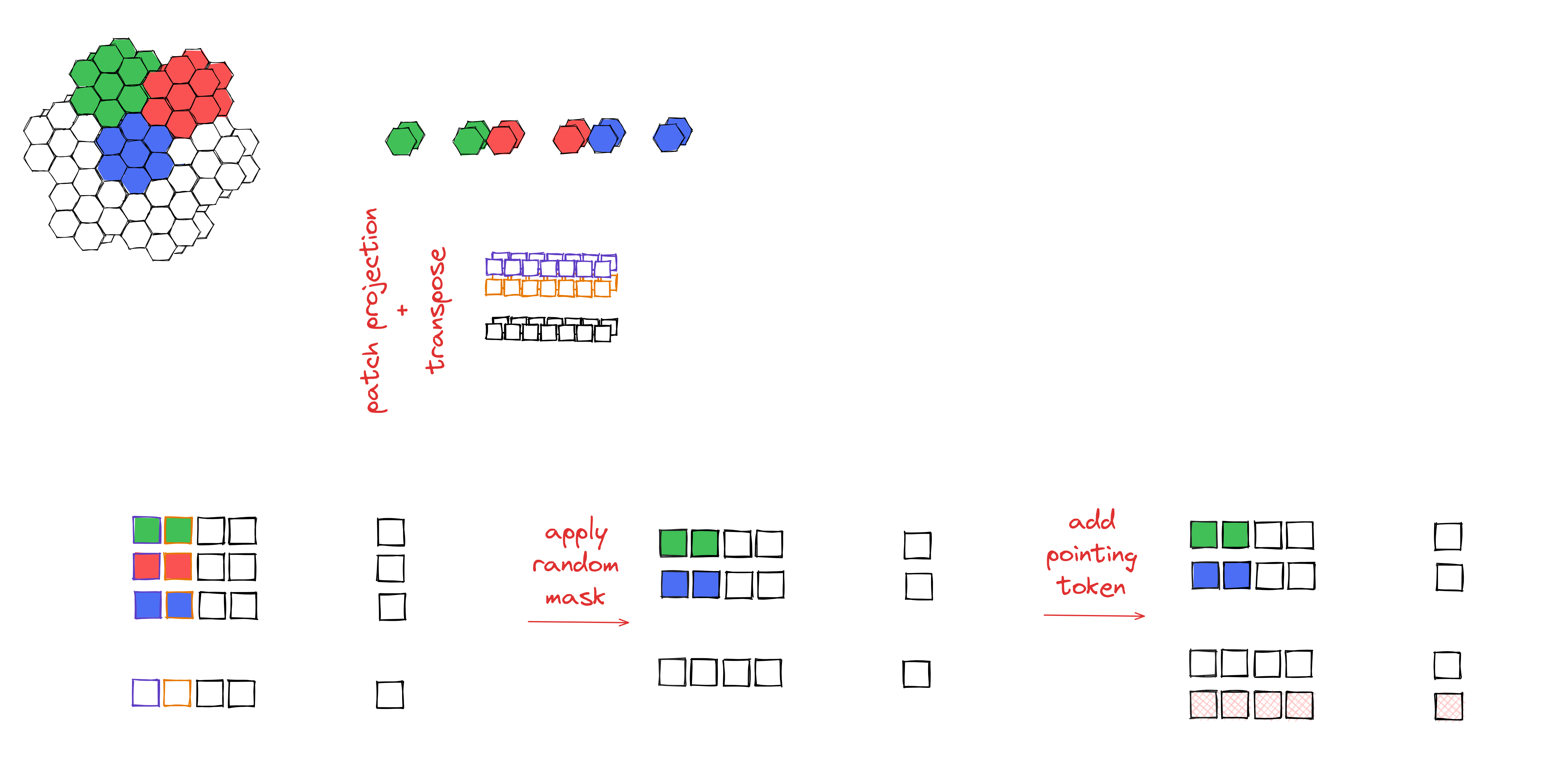
Fine-tuning
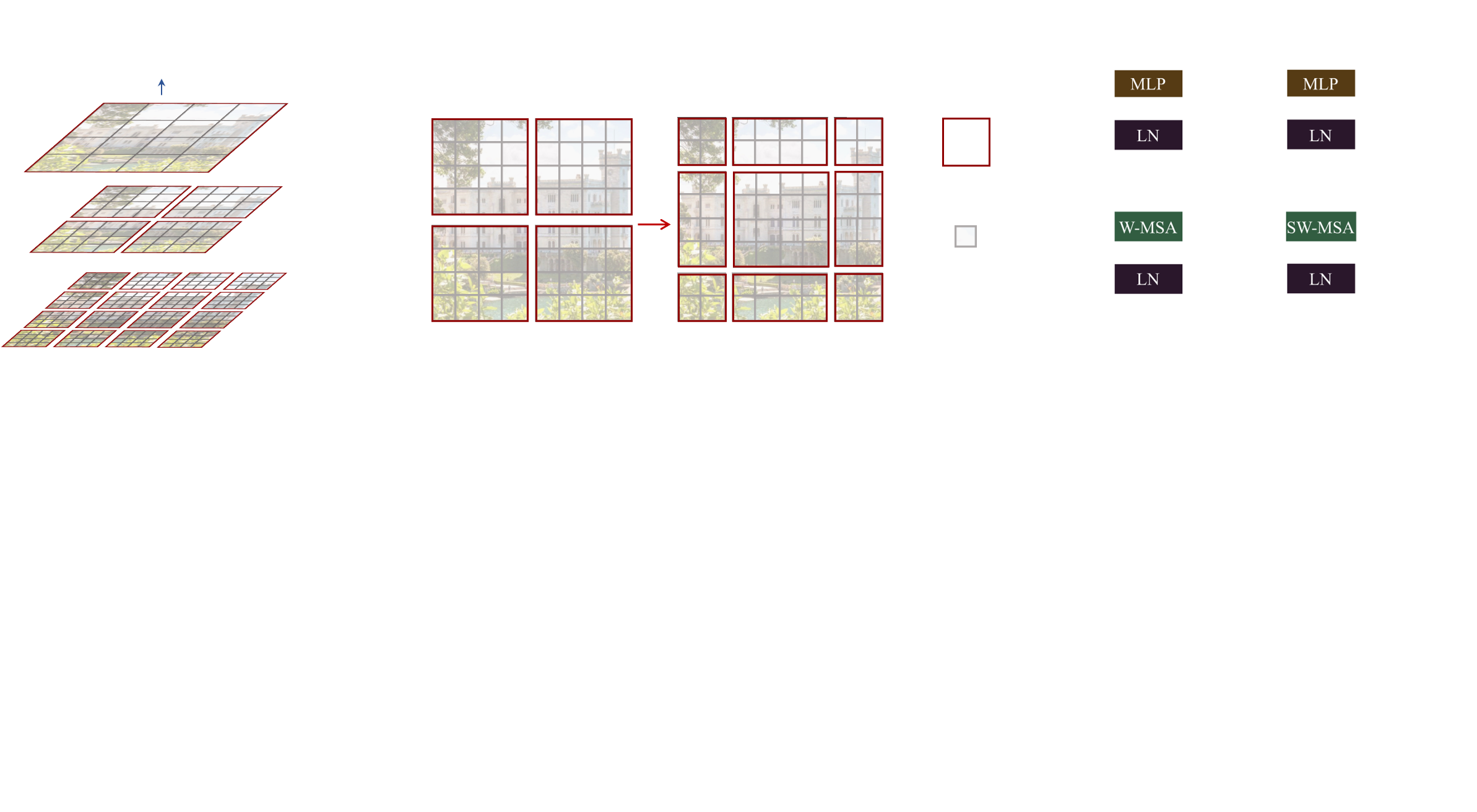
Swin Transformers
Training
Cours scientifiques et techniques (88h / 40h) * Statlearn: challenging problems in statistical learning (04 avril 2022) Société Française de Statistique à Cargèse (21h) * Formation FIDLE «Introduction au Deep Learning» (25 novembre 2021) CNRS - DevLOG / RESINFO / SARI / IDRIS, en ligne (27h) * ESCAPE Data Science Summer School 2022 (20 juin 2022 - 24 juin 2022) ESCAPE Consortium, Annecy (40h)
Formation transversale (7h / 40h) * Anglais scientifique: améliorer la fluidité de ses présentations ORALES (08 décembre 2022 - 8 décembre 2022) CNRS, Grenoble (7h)
Formation à l'insertion professionnelle (en cours de validation) * 1ère année: ~30h équivalement TD * 2ème année: ~60h équivalement TD * 3ème année: en cours
Talks & Articles
Talks * LST meeting Barcelone * LST meeting Munich * Workshop Machine Learning in2p3 Paris * CBMI à venir (20-22 septembre)
Articles (accepted) * CBMI 2023 Articles (to be published) * CBMI version étendue (dans MTAP / Springer) * ADASS for the application on other known sources
Timeline for the last year
Conclusion & Perspectives
Acknowledgments
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()